มารู้จักข้อมูลของเราให้ดีกว่าเดิม
สวัสดีอีกครั้ง กลับมาเจอกันครั้งนี้ เรามีเรื่องสำคัญมาเล่าเกี่ยวกับการทำงานด้านข้อมูล ซึ่งเป็นเรื่องที่ทุกคนควรรู้ก่อนที่จะนำข้อมูลไปใช้งาน…

สวัสดีอีกครั้ง กลับมาเจอกันครั้งนี้ เรามีเรื่องสำคัญมาเล่าเกี่ยวกับการทำงานด้านข้อมูล ซึ่งเป็นเรื่องที่ทุกคนควรรู้ก่อนที่จะนำข้อมูลไปใช้งาน โดยจะแบ่งหัวข้อดังต่อไปนี้ครับ
- แหล่งที่มาของข้อมูล
- ลักษณะไฟล์ข้อมูล
- ลักษณะของข้อมูล
- ประเภทของข้อมูล
ทั้งหมดนี้อ้างอิงจากประสบการณ์ทำงานส่วนนึงที่พบเจอความผิดพลาดในแต่ละส่วนที่แตกต่างกันไป ทั้งเจอคนที่ใช้ไฟล์ผิดประเภท คำนวณตัวเลขไม่ตรง เปิดไปเจอข้อมูลที่ไม่ควรจะเจอ ฯลฯ ถ้าใครไม่อยากทำงานพลาดบ่อยๆ อย่าลืมเช็คเรื่องพวกนี้ก็ที่จะไปทำข้อมูลครับ
- แหล่งที่มาของข้อมูล
ก่อนที่เราจะนำข้อมูลมาใช้เราจำเป็นที่จะต้องรู้แหล่งที่มา และวิธีการเกิดของข้อมูลชุดนั้นในชัดเจนก่อน ใช่ครับ ผมเจอปัญหาลักษณะนี้ตลอดเวลากับการทำงานโดยเฉพาะการทำข้อมูลขนาดใหญ่ที่เรียกว่า Big Data ซึ่งมีการไหลเวียนของข้อมูลจำนวนมหาศาลต่อวัน บางครั้งผู้ใช้งานข้อมูลก็ไม่ได้เข้าใจข้อมูลที่ตัวเองมีอยู่ 100% แต่เรื่องเหล่านี้ล้วนเป็นพื้นฐานสำคัญที่จะทำให้การหาข้อมูลเชิงลึกของเรามีประโยชน์มากหรือน้อยแตกต่างกันไป
หากเรารู้ว่าข้อมูลของเรามีแหล่งที่มาอย่างไร จะเป็นข้อดีที่ทำให้นักวิเคราะห์ข้อมูลทำงานได้ง่ายขึ้นมาก เพราะเราจะรู้ว่าข้อมูลไหนควรใช้เมื่อสถานการณ์แบบใดบ้าง
สิ่งสำคัญของหัวข้อนี้คือ เราควรจะต้องรู้เรื่องระดับชั้นของข้อมูล(Scope) แน่นอนว่าข้อมูลบางชุดมีขนาดที่ไม่เท่ากัน ด้วยเหตุผลทางเทคนิคบางอย่างเราจึงไม่นิยม รวมข้อมูลไว้ที่เดียวแล้วใช้งาน (ปัจจัยด้านความเสถียร ความเร็ว และราคามีผลต่อเรื่องนี้มาก) การนำข้อมูลมาใช้งานร่วมกัน จะต้องพิจารณาถึงความเล็กใหญ่ของข้อมูลเพื่อให้เราวิเคราะห์ได้ถูกต้อง
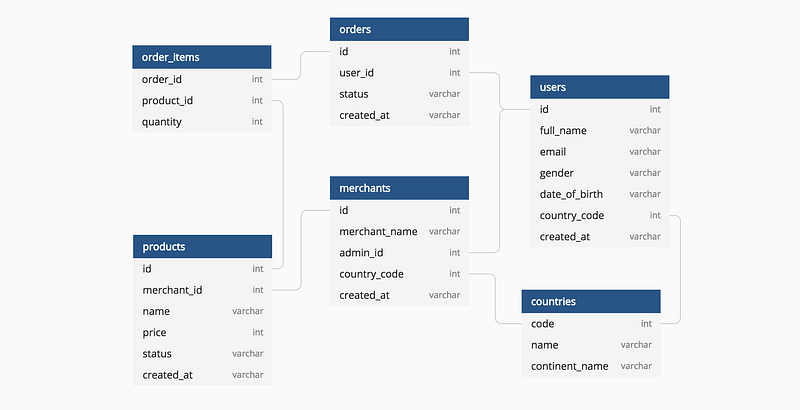
ตัวอย่างเช่น เรามีข้อมูลการซื้อสินค้าของลูกค้า 1 คนที่มีประวัติการใช้งานเว็บไซต์และแอพพลิเคชั่นในช่วงเวลาต่างๆ กับข้อมูล CRM ของลูกค้าทั้งหมด แน่นอนว่าการนับระดับบุคคลมักจะเป็นข้อมูลที่มี SCOPE สูงสุด เพราะเป็นข้อมูลที่มี Primary Key อย่างน้อยก็อาจจะเป็น ID หรือรหัสบางอย่างที่เป็นตัวเชื่อมต่อกับข้อมูลชุดอื่น ๆ เพื่อใช้ในการดูภาพรวมของข้อมูล ส่วนรายละเอียดเกี่ยวกับพฤติกรรมการใช้งานจะเป็นเรื่องที่ลงรายละเอียดไปในแต่ละบุคคลอีกทีนึง
“นาย A ซื้อสินค้า 10 ชิ้นในรอบ 7 วันที่ผ่านมา”
“สินค้า 10 ชิ้นที่ได้รับความนิยมในรอบ 7 วันที่ผ่านมา ถูกซื้อโดยนาย A ,นาย B ,…”
จะเห็นได้ว่าประโยคแรกกับประโยคที่ 2 มีการนำไปสู่การหา Insight ที่แตกต่างกัน
ประโยคแรก เรารู้ว่านาย A ซื้อสินค้าจำนวนมากในรอบ 7 วัน แล้วใครมีพฤติกรรมที่ใกล้เคียงกับนาย A บ้าง เราสามารถแบ่งกลุ่มผู้ใช้งานตามพฤติกรรมการซื้อได้หรือไม่
สินค้า 10 ชิ้นที่นาย A ซื้อมีความเกี่ยวข้องกันและสามารถทำเป็น Package ขายได้หรือไม่ (ซึ่งอาจจะไม่ใช่สินค้าที่ขายได้ดีที่สุดในสัปดาห์นั้น)
นอกจากนี้เรายังสามารถทำแคมเปญที่มุ่งให้คนมาซื้อสินค้าในปริมาณที่มากขึ้นได้ด้วยการใช้โค้ดส่วนลด
ส่วนประโยคที่ 2 เรามองจากผลิตภัณฑ์ที่ถูกซื้อ แล้วนำมาจัดเป็น Product Top 10 แล้วสินค้าเหล่านี้มีคนจำนวนเท่าไรบ้างที่ซื้อภายในช่วงเวลาดังกล่าว สินค้าเหล่านั้นขายได้เป็นช่วงเวลาหรือไม่ เช่น ต้นเดือน กลางเดือน หรือปลายเดือน
หรือสินค้าที่อยู่ในลิสต์ดังกล่าวเป็นที่ต้องการจนทำให้ Demand สูงในบางช่วงเวลาหรือไม่
สิ่งที่เราควรจะต้องระมัดระวังในการใช้ข้อมูลก็คือ เรื่องระดับความเล็กใหญ่ของแต่ละชั้นข้อมูลที่เรามีอยู่ จากประสบการณ์ที่เคยทำงานมาพบว่า 70%ของปัญหาเกิดจากการที่ผู้ใช้งานดึงข้อมูลคนละระดับมาใช้งานร่วมกัน โดยไม่ได้ทำการแปรตัววัดผลให้อยู่ในระดับเดียวกัน ข้อมูลถึงมีความผิดเพี้ยนและไม่เมกเซ้นส์เกิดขึ้น โดยเฉพาะตัวปรับเซียนอย่าง Google Analytics ที่ทำให้คนหงายหลังมาแล้วนับไม่ถ้วน
2. ลักษณะไฟล์ข้อมูล
หัวข้อนี้จะมีความเกี่ยวข้องกับ 2 หัวข้อสุดท้ายด้วยครับ เพราะฉะนั้นใครที่กำลังหลับอยู่ตั้งใจตื่นขึ้นมาอ่านได้แล้ว
เนื่องจากไฟล์ข้อมูลที่เราสามารถใช้งานได้มีหลายสกุลมาก ผมจึงขอแบ่งไฟล์ข้อมูลตามนี้ คือ
2.1 Structured data ข้อมูลที่มีโครงสร้างชัดเจน มีรูปแบบง่ายต่อการนำไปใช้งาน ยกตัวอย่าง เช่น Google Sheet , Microsoft Excel เป็นต้น
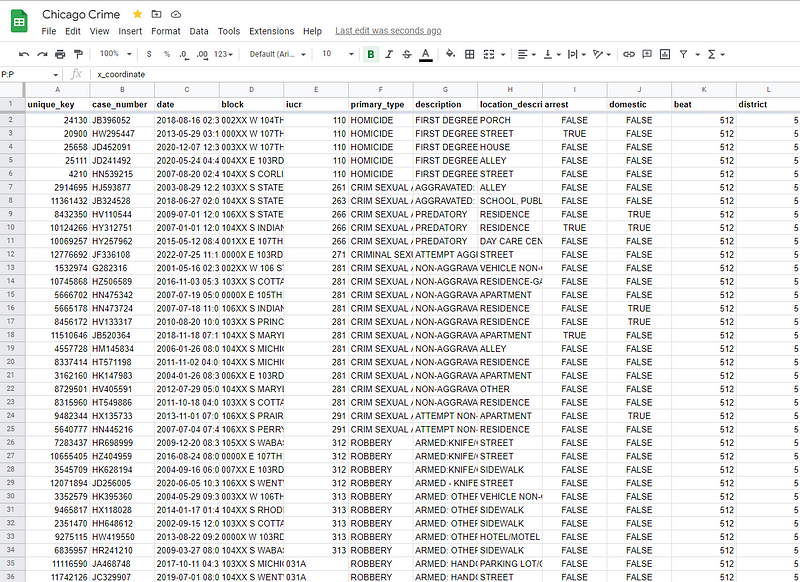
2.2 Semi Stuctured data ข้อมูลที่ไม่ได้มีการจัดโครงสร้างไว้ให้ใช้งานได้ง่าย แต่มี Index กำกับข้อมูลทำให้สามารถเรียกใช้งานได้ เช่น XML, CSV หรือ JSON
<!--ตัวอย่าง XML File-->
<?xml version="1.0" encoding="UTF-8"?>
<!--Header-->
<feed xmlns:vc="http://www.w3.org/2007/XMLSchema-versioning"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:noNamespaceSchemaLocation="http://www.google.com/shopping/reviews/schema/product/2.3/product_reviews.xsd">
<version>2.3</version>
<!--Body-->
<Product>
<Product_Name>Samsung S23 Ultra </Product_Name>
<Product_sku> Sam-001 </Product_sku>
</Product>
<Product>
<Product_Name>Samsung S23 </Product_Name>
<Product_sku> Sam-002 </Product_sku>
</Product>
</feed>//ตัวอย่าง Json file ปกติจะเก็บข้อมูลเป็น Object และถ้ามีข้อมูลหลายๆตัวจะใช้เป็น Array ครอบ
//Object เก็บเป็น Key ,Value ข้างใน {}
[
{ "Product" : "Samsung S23 Ultra",
"Product_sku" : "Sam-001"
},
{ "Product" : "Samsung S23",
"Product_sku" : "Sam-002"
}
]2.3 Unstructured data ไม่มีโครงสร้างใดๆ เลย ตัวอย่างข้อมูลประเภทนี้ก็เช่น รูปภาพ เพลง คลิปวิดีโอ โพสบ่นๆ บนโซเชียลมีเดีย กระทู้ความเห็นตามเว็บบอร์ดต่างๆ หรือแม้แต่ไฟล์ข้อมูลเอกสารประเภท Word และ PDF
แม้จะเป็น Unstuctured data ก็ไม่ใช่ว่าเราจะไม่สามารถวิเคราะห์มันได้ ยกตัวอย่างวิดีโอบน YouTube เราสามารถใช้ Computer vision , OpenCV มาช่วยในการวิเคราะห์เนื้อหาภายในวิดีโอได้เช่นกัน
สำหรับงานสาย Data Analyst ไฟล์ที่เรามักจะพบเจอบ่อย ๆ สำหรับงานที่ใช้ข้อมูลขนาดใหญ่ที่มีโครงสร้าง เช่น Arvo , Parquet และ ORC สามารถอ่านได้ตามนี้ (ผมไม่ค่อยได้เจอกับ ORC มากเท่ากับสองตัวแรก ส่วนมิวน่าจะเจอมาหมดแล้ว)
ดูบทความของมิวได้ตามนี้เลย

3.ลักษณะของข้อมูล
ลักษณะของข้อมูลที่เราจะนำมาใช้งานเป็นสิ่งสำคัญที่เราควรจะต้องรู้จักมันเป็นอย่างที่ ตอนที่ทำงานจะได้เกิดความผิดพลาดได้น้อยที่สุด หลายๆครั้งความผิดพลาดในเรื่องของข้อมูลก็มาจากการที่เรารู้จักข้อมูลตัวเองไม่ดีพอจนไม่สามารถ Clean ข้อมูลได้ถูกต้อง
แต่ก็มีส่วนมากที่นำข้อมูล 2 แบบ ด้านล่างนี้มารวมกันอย่างไม่ตั้งใจ ทำให้ทิศทางในการวิเคราะห์ข้อมูลผิดออกไปจากรูปแบบเดิมที่ควรจะเป็น
3.1 ข้อมูลเชิงคุณภาพ คือข้อมูลที่เราไม่สามารถบอกได้ว่ามีจำนวนมากหรือน้อย ผ่านตัวเลขหรือสถิติต่างๆ แต่จะสามารถอธิบายความแตกต่างระหว่างข้อมูลแต่ละชุดได้ผ่านการตีความหมายตามบริบทนั้น ๆ
ยกตัวอย่างข้อมูล เช่น การเขียน Reviews , การให้สัมภาษณ์ เป็นต้น
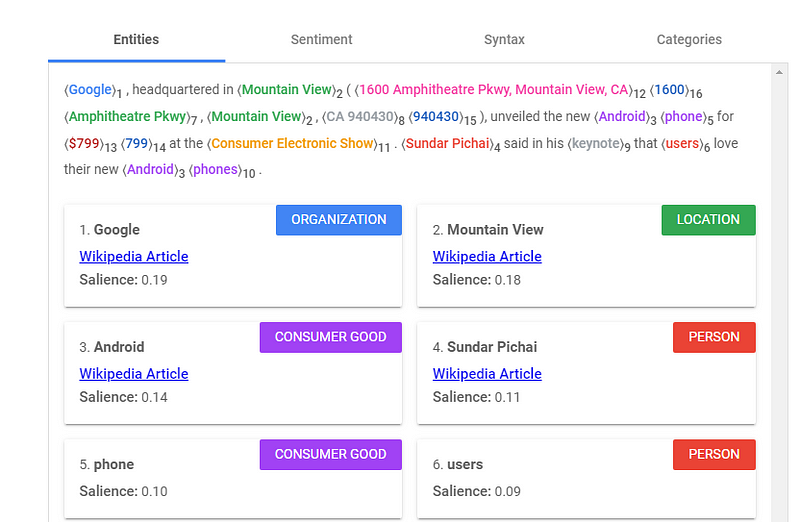
ปัจจุบันศาสตร์ของการทำข้อมูลสามารถนำข้อความที่ถูกบอกเล่าในเชิงคุณภาพ มาใช้ในการประมวลผลผ่านวิธีการต่าง ๆ เช่น การทำ Sentiment Analysis เพื่อตีความประโยคนั้นๆ ,การทำ Entities เพื่อระบุ Label ลงในคำแต่ละคำของประโยคนั้นๆ หากมีโอกาสจะนำมาเขียนในบล็อกอย่างละเอียดในครั้งต่อ ๆไป
3.2 ข้อมูลเชิงปริมาณ คือข้อมูลที่มีความตรงชัด วัดได้ เราสามารถบอกจำนวนได้ตามตยกตัวอย่างข้อมูล เช่น จำนวนผู้เข้าใช้งานเว็บไซต์ ,จำนวนผู้ดาวน์โหลดแอพลิเคชั่น ,จำนวนคนที่ฟังวิทยุออนไลน์ เป็นต้นัวเลขและค่าสถิติที่ปรากฎ
โดยพื้นฐานแล้วเราควรจะเข้าใจก่อนว่าสถิติที่พูดถึงนั้นแบ่งออกเป็นสถิติ 2 ประเภท
- สถิติเชิงพรรณนา (Descriptive statistics) หมายถึงสถิติที่ใช้ในการบรรยายลักษณะข้อมูลทั่วไป เช่น ค่าเฉลี่ย มัธยฐาน ฐานนิยม ร้อยละ ส่วนเบี่ยงเบนมาตรฐาน ความแปรปรวน เป็นต้น
- สถิติเชิงอนุมาน (Inferential Statistics) หมายถึง สถิติที่ใช้ในการเก็บรวบรวมข้อมูลโดยอาศัยความน่าจะเป็นเข้ามาประยุกต์ใช้ด้วย สถิติประเภทนี้จะใช้การประมาณค่าทางสถิติ การทดสอบสมมติฐาน (T-test, F-test ) การวิเคราะห์หาความสัมพันธ์เชิงเส้นแบบถดถอย หรือที่เรารู้จักกันในชื่อ Linear Regression นั่นเอง
โดยจะต้องคำนึงถึงระดับตามแปรที่เป็น Nominal , Ordinal และ Scale ที่จะส่งผลต่อการเลือกใช้ค่าสถิติต่างๆ ในการวัดผลและจะส่งผลที่แม่นยำต่อการทำนายของโมเดลทางสถิติของเราได้แม่นยำมากขึ้น
4.ประเภทของข้อมูล
สำหรับข้อมูลเชิงปริมาณ เรามักจะเก็บข้อมูลมาโดยมี Format ที่แตกต่างกัน แต่ละภาษาก็มีวิธีการเรียก Data Type ของตัวเองต่างกัน ไม่ว่าจะเป็น SQL , Python , Javascript (ปวดหัวสุด เพราะบวก Int กับ String แปลกๆ จึงไม่ค่อยนิยมนำไปใช้ทำข้อมูลเท่ากับสองภาษาแรก แต่มักจะใช้เป็นตัวการในการเรียกข้อมูลจาก API และการส่งค่าด้วย Analytics Platform หรือ CDP ต่างๆ )
เรามาดูกันดีว่าแต่ละภาษาเราต้องเข้าใจอะไรบ้าง หลักคือชนิดของข้อมูลที่เราได้รับมาจะถูกเรียกชื่อต่างกัน แต่จะสามารถใช้งานได้แม้เขียนด้วยคนละภาษาก็ตามยกตัวอย่าง เช่น
“Array บน SQL และ Array ของ Javascript จะมีค่าเหมือนกับ List ใน Python”
“Object ใน Javascript ก็จะมีค่าเหมือนกับ Set ใน Python”
วิถีของคนทำข้อมูลที่แท้จริงก็คือการนำเข้าข้อมูลต่างๆ ให้อยู่ในรูปแบบที่พร้อมใช้สำหรับบุคคลทั่วไป โดยที่ใส่เพียง Data Dictionary ให้ผู้ใช้งานใช้ต่อได้สะดวก ลดการเกิด Human Error ให้มากที่สุดเท่าที่จะเป็นไปได้
ประเภทของข้อมูลใน JavaScript
var age = 18; // number
var name = "Jane"; // string
var name = {first:"Jane", last:"Doe"}; // object
var truth = false; // boolean
var sheets = ["HTML","CSS","JS"]; // array
var a; typeof a; // undefined
var a = null; // value null
typeof age //คำสั่ง Check Data Type Javascript
ประเภทของข้อมูลใน SQL
เนื่องจากชนิดของข้อมูลใน SQL มีจำนวนเยอะและมีความละเอียดมาก ๆ ชาว Data Analyst ทั้งหลายจึงควรจะต้องระวังการใช้งานโดยตรวจสอบชนิดของคอลัมน์ที่จะนำมาใช้งานทุกครั้ง สามารถศึกษาเพิ่มเติมได้ ที่นี่
String Data Types
CHAR(size) ใช้กับตัวอักษร ตัวเลขและอักขระพิเศษที่มีความยาวไม่เกิน 255 Characters
VARCHAR(size) ใช้กับตัวอักษร ตัวเลขและอักขระพิเศษที่มีความยาวไม่เกิน 65,535 Characters
Numeric Data Types
INTEGER(size) ใช้กำหนดค่าที่เป็นตัวเลขจำนวนเต็ม
FLOAT(size, d) ใช้กำหนดค่าตัวเลขที่มีตำแหน่งทศนิยม
Date and Time Data Types
DATE ใช้เกี่ยวกับวันที่ เช่น YYYY-MM-DD
DATETIME(fsp) ใช้เกี่ยวกับวันที่ + ช่วงเวลา เช่น YYYY-MM-DD hh:mm:ss
TIMESTAMP(fsp) ใช้เป็นชุดตัวเลข timestamp เช่น 1673422922015ประเภทของข้อมูลใน Python
ปกติเราจะใช้ข้อมูลแบบในบน Panda , Numpy และ Pyspark ดังนั้นก่อนที่เราจะเริ่มรันข้อมูลจริงๆ ควรจะมีการ Log Type ของไฟล์ของมาเช็คก่อน
x = "Hello World" #str
x = 20 #int
x = 20.5 #float
x = 1j #complex
x = ["apple", "banana", "cherry"] #list
x = ("apple", "banana", "cherry") #tuple
x = range(6) #range
x = {"name" : "John", "age" : 36} #dict
x = {"apple", "banana", "cherry"} #set
x = frozenset({"apple", "banana", "cherry"}) #frozenset
x = True #boolean
x = b"Hello" #bytes
x = bytearray(5) #bytearray
x = memoryview(bytes(5)) #memoryview
x = None #NoneType
type(x) #คำสั่ง Check Data Type Pythonไม่ว่าข้อมูลจะถูกเก็บในลักษณะใดก็ตาม Data Analyst ก็จะมีบทบาทต่อข้อมูลนั้นๆ เพื่อนำมาปรับใช้ให้เหมาะกับ Use Case ที่ทางบริษัทต้องการ เราอาจจะต้องทำการ Transform Data ให้เรียบร้อยก่อน ซึ่งอาจจะใช้ระยะเวลาค่อนข้างนาน แนะนำว่าให้ปรึกษากับเจ้าของข้อมูลในเรื่องของการนำข้อมูลไปใช้ให้รอบคอบ จะได้ไม่ต้องทำ Transform Data หลายครั้ง และอาจช่วยประหยัดงบในการทำข้อมูลไปได้มาก
อย่าลืมว่าหลังจากที่เรารู้จักข้อมูลที่อยู่ในมือแล้ว เราควรจะต้องศึกษา Business ของข้อมูลที่เราถืออยู่ในแง่ของการนำไปใช้ประโยชน์ให้เหมาะสม นอกจากนี้เราควรจะต้องไปศึกษา case study จากการนำข้อมูลมาใช้ที่ปัจจุบันมีแชร์มากมายอยู่บนโลกอินเทอร์เน็ตมาเพื่อเพิ่มมุมมองในการวิเคราะห์ของเราด้วย


