ภาษา Python กับงานสาย Data
แนะนำภาษา Python กับสายงาน Data

สำหรับใครที่เพิ่งย้ายสายงานมาทำสาย Data ทุกคนน่าจะคุ้นเคยกับการใช้ Excel / Google Sheet เป็นหลัก หรือแม้กระทั่งการใช้ SQL เพื่อดึงข้อมูลจาก Database ของบริษัทออกมาทำงานกันบ้างแล้ว แต่บางคนที่ไม่ได้ทำงานสาย Data หรือเป็น Developer อาจจะยังไม่ชินกับภาษา python มากนัก วันนี้ผมจึงจะมาแนะนำเกี่ยวกับภาษานี้กันแบบง่าย ๆ โดยไม่ลงโค้ดมากนัก
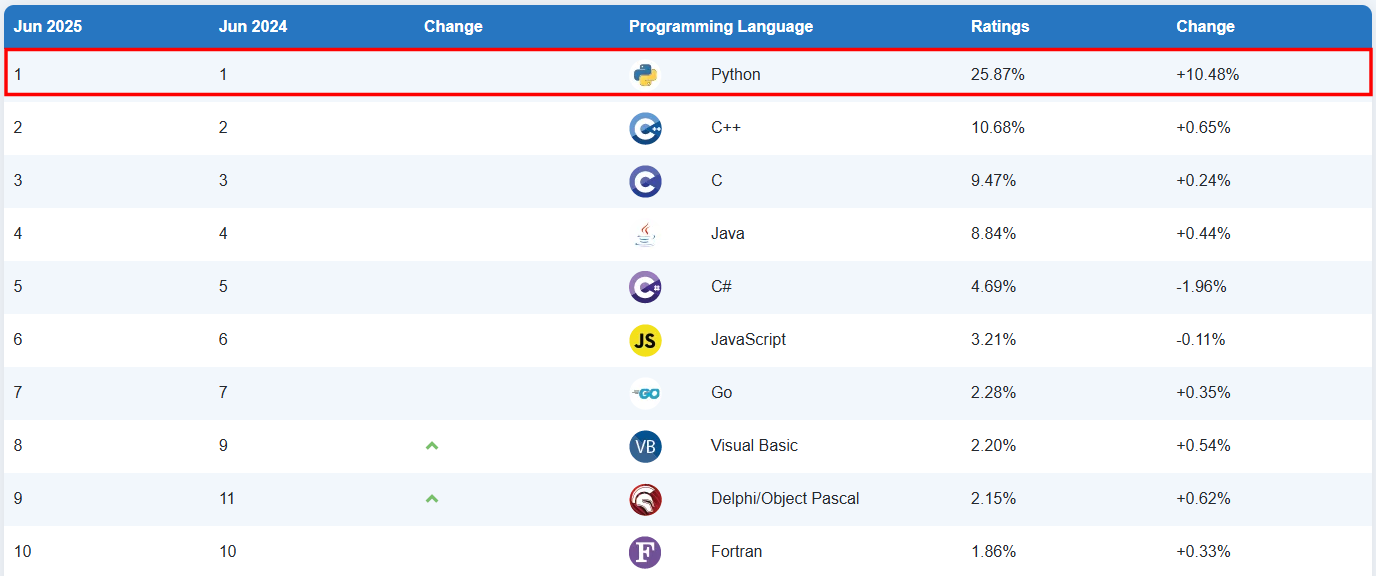
ภาษา Python เป็นภาษาที่นิยมใช้งานอย่างมากสำหรับงานทั่วไป และเหมาะสำหรับผู้เริ่มต้นการเขียนโปรแกรมแบบพื้นฐาน ภาษา Python ยังมี community ขนาดใหญ่ที่เราสามารถเจอคำตอบของปัญหาที่เรากำลังเผชิญหน้าอยู่ ทำให้เราสามารถแก้ไขปัญหาที่มีได้ง่ายขึ้น นอกจากนี้ Python ยังมี Library มากมายให้เราสามารถเลือกใช้งานได้
สำหรับงานสาย Data ผมขอแบ่งหัวข้อตามนี้ครับ เรียงตามความเข้มข้นในการใช้งานภาษา Python จากมากที่สุด
- Data Engineer (วิศวกรข้อมูล)
- Data Scientist (นักวิทยาศาสตร์ข้อมูล)
- Data Analyst (นักวิเคราะห์ข้อมูล)
ภาษา Python กับ Data Engineer
สำหรับงานสาย Data Engineer จะเกี่ยวข้องกับการดูแล จัดการ และเปลี่ยนแปลงข้อมูลให้อยู่ในรูปแบบที่พร้อมใช้งานได้ ซึ่งบางที่อาจจะ Optimize Performance ด้วยการเลือกภาษาอื่น ๆ ที่สามารถทำงานได้เร็วกว่า Python ได้ (เช่น Go , C, Java, Rust เป็นต้น) แต่ทั้งนี้ทั้งนั้นมันจะขึ้นอยู่กับงานที่ได้รับมอบหมาย รวมถึงระยะเวลาที่เราต้อง develop pipeline ในการทำข้อมูลด้วย
ภาษา Python จะช่วยให้ Data Engineer สามารถปรับเปลี่ยนข้อมูลที่มีขนาดใหญ่ได้ดี เนื่องจากมีวิธีการจัดการกับข้อมูลแต่ละรูปแบบได้หลายหลาย เช่น Pandas , Polar , DuckDB, Pyspark เป็นต้น โดยที่รูปแบบการเขียนโปรแกรมจะขึ้นอยู่กับงานที่ได้รับมอบหมายมาในแต่ละ Task
นอกจากการจัดการข้อมูลแล้ว Data Engineer ยังมีบทบาทสำคัญในการวางโครงสร้างข้อมูล รวมถึงการเชื่อมต่อ เพื่อนำเข้า / ส่งออกข้อมูลจำนวนมากให้มีความเหมาะสมกับการใช้งานของผู้ใช้งานทั่วไป เช่น การเขียนสคริปต์เพื่อเชื่อมต่อกับ Database Server , การสร้าง Airflow สำหรับการดำเนินงานแบบอัตโนมัติ หรือแม้กระทั่งการเชื่อมต่อกับ Cloud platform เช่น AWS , Google Cloud , Azure เป็นต้น
ตัวอย่างเครื่องมือที่ใช้สำหรับสายงาน Data Engineer
Pandas การทำความสะอาด (Cleaning), จัดการ (Manipulation), และแปลงข้อมูล (Transformation) สำหรับชุดข้อมูลที่ไม่ใหญ่มาก หรือในขั้นตอนการพัฒนาและการทดสอบ (Development and Testing) ก่อนที่จะนำไปใช้กับเครื่องมือ Big Data

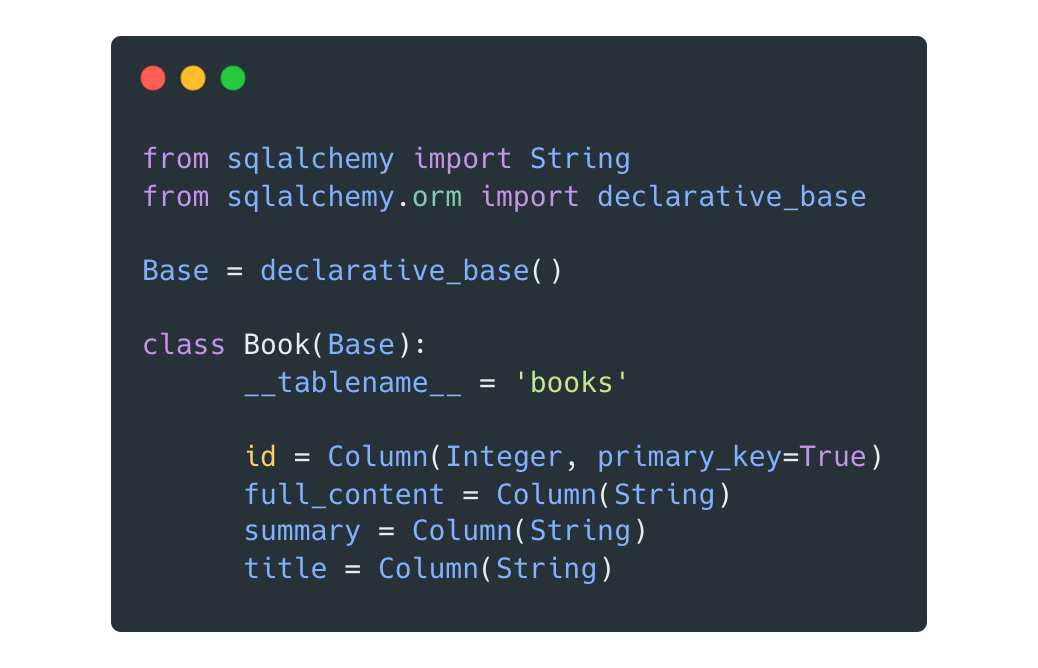
SQLAlchemy (Database Toolkit and ORM) เป็น library สำหรับการ เชื่อมต่อ (Connecting), โต้ตอบ (Interacting), และจัดการ (Managing) กับฐานข้อมูลเชิงสัมพันธ์ (RDBMS Database) ใช้ในการดึงข้อมูลจากแหล่งต่างๆ, เขียนข้อมูลลงฐานข้อมูลปลายทาง, หรือแม้แต่จัดการ Schema ของฐานข้อมูล
อย่างไรก็ตามการทำงานที่ดีเกี่ยวกับ Database ควรจะต้องเข้าใจเรื่อง Database ระดับพื้นฐานก่อน เช่น การกำหนด schema การสร้าง Index ,Primary key, foreign key รวมถึงการจัดการเรื่องความปลอดภัยและความเร็วของข้อมูลที่ผู้ใช้งานจะต้องนำไปใช้
นอกจากนี้งานบางอย่างของสาย Data Engineer อาจจะเกี่ยวข้อมูลฐานข้อมูลประเภท Nosql Database เช่น Mongo DB , Neo4j , Cassandra ซึ่งจะมีความซับซ้อนในการเก็บข้อมูลมากกว่าที่คนทั่วไปเข้าใจในรูปแบบของ Table
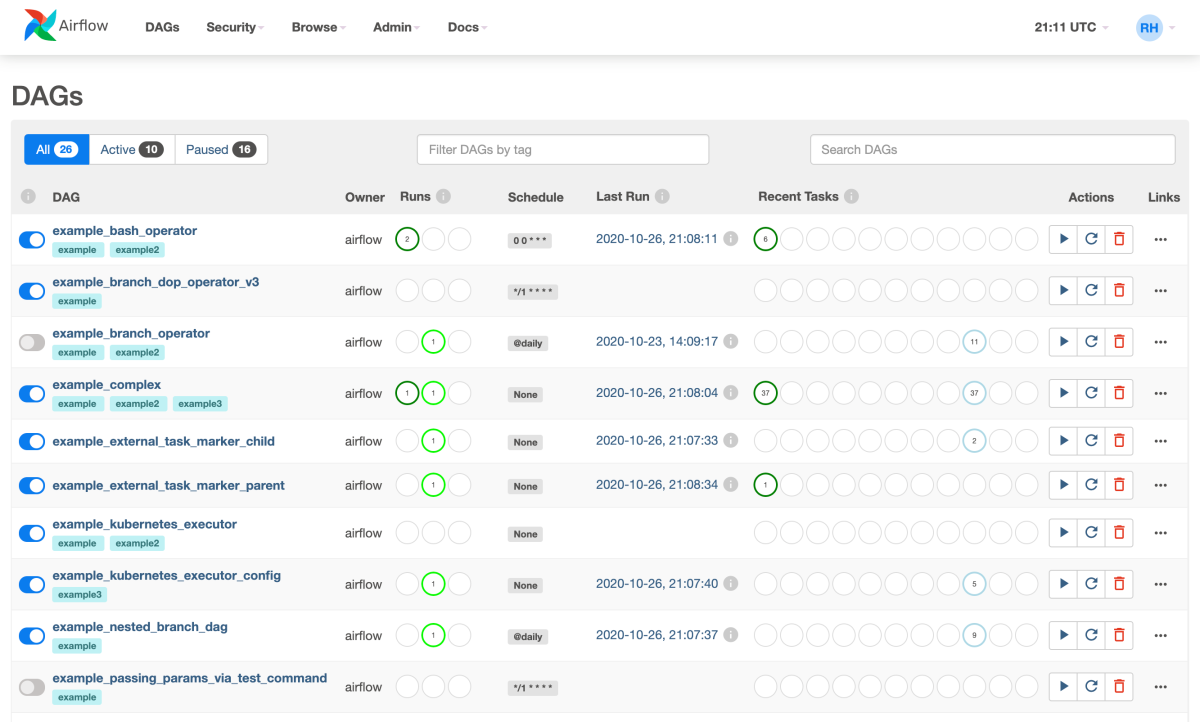
Apache Airflow (Workflow Management Platform) เป็นแพลตฟอร์มที่ ใช้ Python ในการสร้าง function การทำงาน, กำหนดเวลา (Cronjob), มอนิเตอร์ ดู Logs, จัดการ Task ต่างๆ ได้ง่ายและเป็นระบบ
Workflow (DAGs) ซึ่งเป็นหัวใจสำคัญของ Data Pipeline เหมาะสำหรับการรัน ETL/ELT Jobs ที่มีความซับซ้อนและมีการพึ่งพากัน โดยเฉพาะการจัดการข้อมูลขนาดใหญ่ที่มีการไหลเข้าออกตลอดเวลา
Spark (PySpark) คือ Python API สำหรับ Apache Spark ซึ่งเป็นเฟรมเวิร์กสำหรับการประมวลผลข้อมูลขนาดใหญ่แบบกระจาย (Distributed Data Processing) เหมาะสำหรับงาน ETL/ELT ที่ต้องการประมวลผลข้อมูลหลายเทราไบต์หรือเพตาไบต์
ปกติไฟล์ขนาดใหญ่ลักษณะนี้เราจะไม่เก็บในรูปแบบ csv , xlsx ทั่วไป ดังนั้น PySpark จึงเหมาะกับงานขนาดใหญ่มาก ๆ ถ้าเป็นงานที่มีขนาดไม่ใหญ่มาก โดยทั่วไปเราจะใช้เป็น Pandas แทน
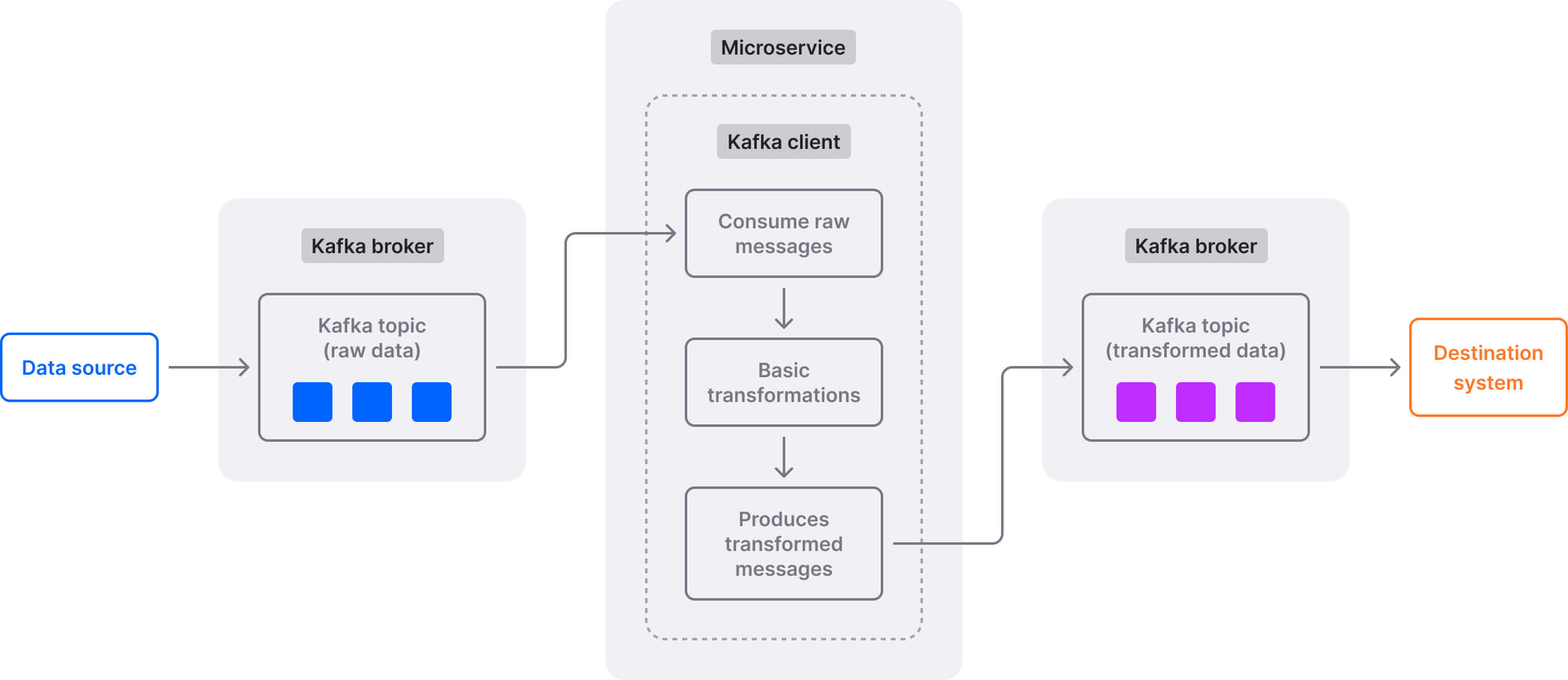
Apache Kafka Client Libraries สำหรับ Data Engineer ที่ทำงานกับ Streaming Data และ Event-driven architectures Kafka เป็น Message Broker ที่นิยมใช้ และไลบรารีเหล่านี้ช่วยให้ Python Application สามารถ Publish (ส่ง) และ Consume (รับ) ข้อความ จาก Kafka Topic ได้
ภาษา Python กับ Data Scientist
Data Scientist เป็นตำแหน่งที่ใช้ความรู้ทางสถิติเพื่อทำนายผลลัพธ์จากข้อมูลที่มีอยู่อย่างมีประสิทธิภาพสูงสุด โดยใช้วิธีการต่าง ๆ เกี่ยวกับโมเดลสถิติเพื่ออ้างอิงความเป็นไปได้อย่างมีนัยสำคัญ
ขั้นตอนการทำงานของสาย Data Scientist จะมีลำดับตามต่อไปนี้
1.การระบุเป้าหมายของการวัดผล / ทำนายผล ตั้งสมมติฐาน ตัวแปรต้น และตัวแปรตาม
2.การรวบรวมข้อมูล เกี่ยวกับคุณลักษณะ พฤติกรรม และบริบทของกลุ่มเป้าหมาย
3.การเตรียมข้อมูล การทำความสะอาดข้อมูล และการแปลงข้อมูลให้เหมาะสมกับการทำนายสถิติ
4.การเลือกโมเดลให้เหมาะสมกับบริบทของข้อมูล และโจทย์การทำงาน
5.การทดสอบโมเดล และประเมินผล (Train model & Evaluation) โดยแบ่งข้อมูลออกเป็นชุด Train & Test เพื่อทำสอบความแม่นยำก่อนนำไปใช้งานจริง
6.การปรับจูน (Model Tuning) การปรับค่า parameter และการจัดการปัญหา Overfitting / Underfiiting
7.การทำนายและการนำไปใช้ (Prediciton & deployment) นำโมเดลที่ผ่านการปรับจูนไปใช้กับงาน และนำไปใช้สื่อสารกับกลุ่มเป้าหมายที่มีความแตกต่างกันตามลักษณะของโมเดลนั้น ๆ
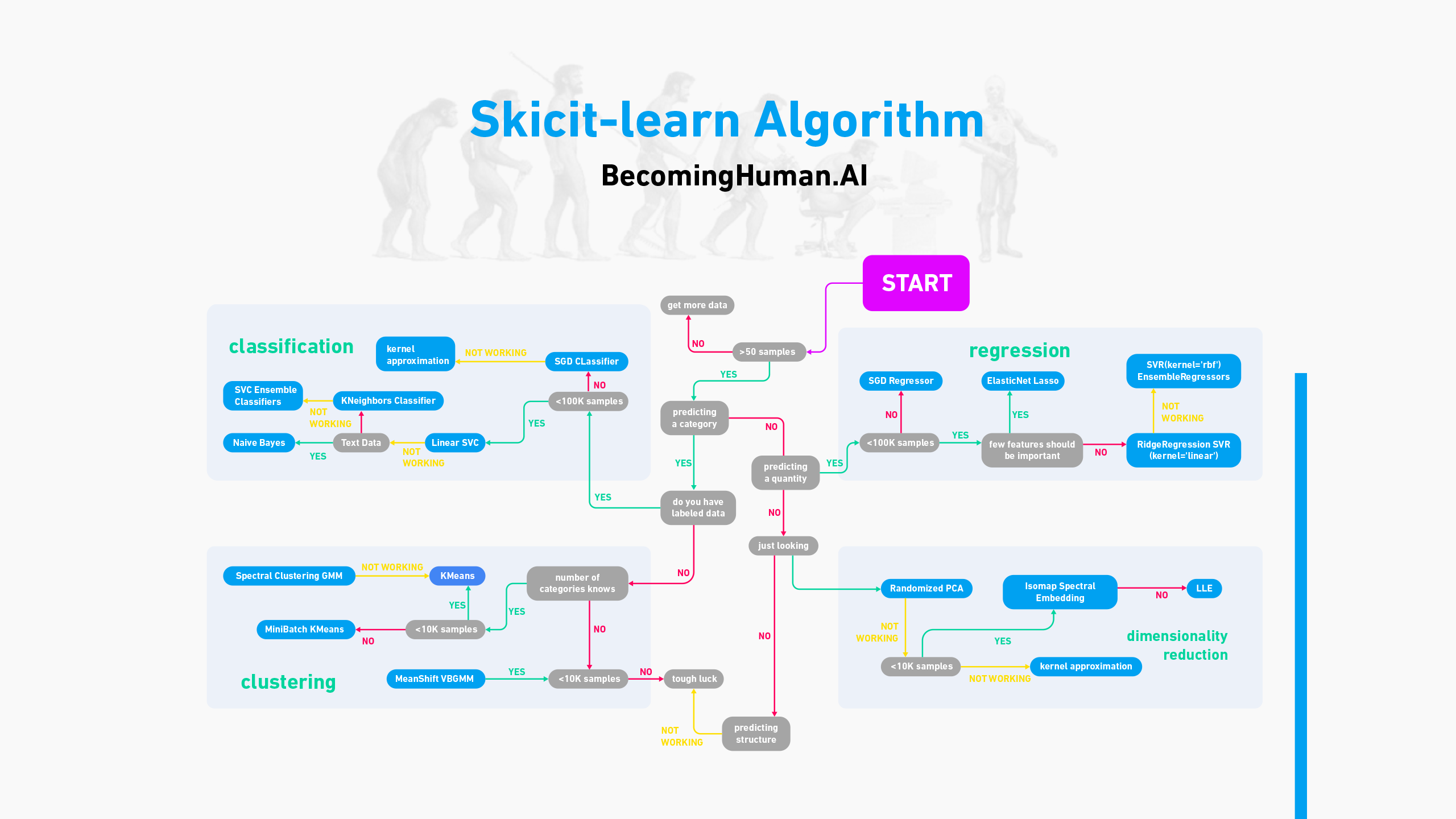
Scikit-learn เป็น Library ที่ Data Scientist ใช้งานบ่อยมาก เนื่องจากเป็น Library ที่มี Algorithm มากมายสำหรับการจำแนกประเภท (Classification), การวิเคราะห์การถดถอย (Regression) , การจัดกลุ่ม (Clustering) โดยที่ผู้ใช้งานจะต้องมีความเข้าใจเกี่ยวกับวิธีการวิเคราะห์ในแต่ละโมเดลก่อน ถึงจะสามารถใช้งานได้อย่างเต็มประสิทธิภาพ
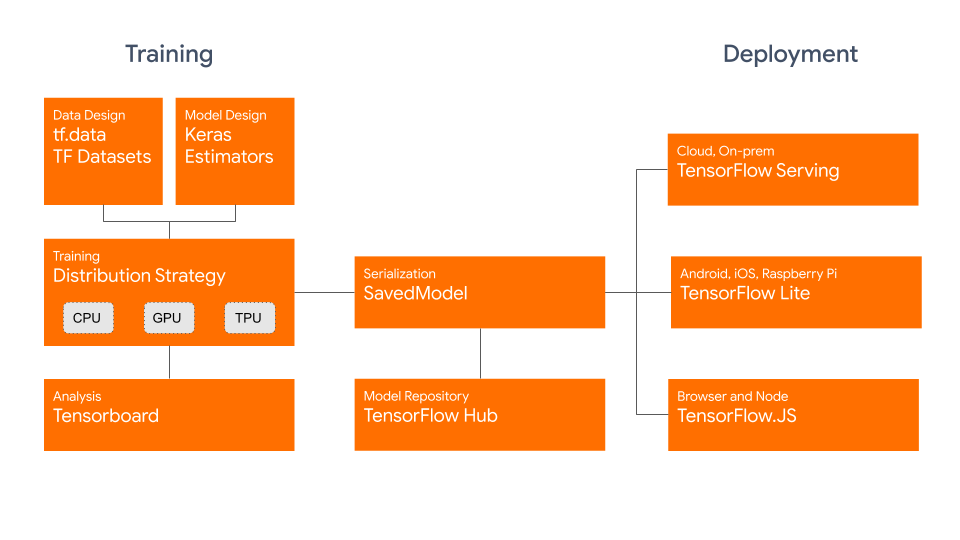
Tensorflow/Keras , Pytorch ใช้สำหรับงานสาย Deep Learning และ Machine Learning ที่ซับซ้อน เช่น ภาษา ภาพ และเสียง ทำให้การสร้างโมเดลสำหรับการวิเคราะห์ง่ายขึ้น ตัวอย่างเช่น การใช้ Tensorflow สำหรับการทำ image recognition เพื่อจดจำใบหน้าพนักงาน หรือการทำ OCR เพื่ออ่านป้ายทะเบียนรถยนต์ ให้มีความแม่นยำสูงสุด
นอกจากนี้ยังมีการประยุกต์ใช้หลักการทางสถิติกับข้อมูลเชิงธุรกิจ ยกตัวอย่างประโยชน์ในการใช้งานเกี่ยวกับ Propensity model ที่ใช้ในการทำนายความน่าจะเป็นที่ผู้ใช้งานจะทำบางอย่างในอนาคต เช่น
Marketing : ความน่าจะเป็นที่ลูกค้าจะซื้อสินค้า/บริการ หรือใช้งานโปรโมชั่น คลิกโฆษณา หรือมีแนวโน้มที่จะยกเลิกบริการ
Risk Managment : ความน่าจะเป็นที่ลูกค้าจะทุจริต / ผิดนัดชำระหนี้
Heathcare : ความน่าจะเป็นที่ผู้ป่วยจะเกิดภาวะแทรกซ้อน / ตอบสนองต่อการรักษา
ทุกขั้นตอนที่ Data Scientist ทำงาน สามารถทำได้โดยผ่านภาษา Python ทั้งหมด เริ่มต้นตั้งแต่การนำเข้าข้อมูลตลอดจนถึงการประมวลผลข้อมูลด้วยโมเดล ทั้งนี้ผู้ใช้งานควรจะต้องเข้าใจหลักการทางสถิติ ข้อจำกัด และรูปแบบของโมเดลอย่างดี ถึงจะใช้งานได้อย่างมีประสิทธิภาพ
ภาษา Python กับ Data Analyst
หากใครย้ายสายจากสายอื่นๆ มา คงจะคิดว่าการใช้ Python เป็นเรื่องเกี่ยวกับการเขียนโค้ดที่น่าจะมีความยากในระดับ ผมอยากให้ลองมองหน้าที่ของ Data Analyst ก่อน ว่าโดยทั่วไปแล้วเราทำอะไรบ้าง และงานแต่ละส่วนปกติเราใช้โปรแกรมอะไร และสามารถทดแทนได้ด้วย Python ได้อย่างไรบ้าง
ขั้นตอนการทำงานของ Data Analyst แบบทั่วไป
- การตั้งคำถาม (Ask) ระบุปัญหาที่ต้องการคำตอบ และคิดแบบเป็นระบบ
- การเตรียมข้อมูล (Prepare data) รวบรวมข้อมูลจากแหล่งที่มา ที่มีความน่าเชื่อถือ
- การจัดการข้อมูล (Process / test / clean / transform) ตรวจสอบคุณภาพข้อมูล
- การวิเคราะห์ข้อมูล (Analyze) หารูปแบบของข้อมูล และหาจุดสำคัญของคำตอบ
- การนำเสนอข้อมูล (Visualization) นำเสนอผ่าน Visual ที่ง่ายต่อการเข้าใจ
- การนำข้อมูลไปใช้ (Apply to Strategy) นำข้อมูลไปประยุกต์ใช้กับแผนงาน
จริง ๆ แล้ว ผมไม่คิดว่า Data Analyst จะใช้ python น้อยกว่าตำแหน่งอื่น ๆ ที่กล่าวมาด้านบนซะทีเดียว บางครั้ง Data Analyst อาจจะมีความถี่ในการใช้ภาษา python มากกว่าด้วยซ้ำ แต่เนื่องจากงานสาย Data Analyst จะให้น้ำหนักกับการวิเคราะห์ข้อมูลมากกว่า ซึ่ง Tools ที่ใช้จะแบ่งออกเป็น 3 รูปแบบหลัก ๆ ทำให้อาจจะไม่ได้ใช้ library ที่มีความซับซ้อนสูงเท่ากับ 2 ตำแหน่งที่กล่าวมาด้านบน
- Database Tools (ใช้สำหรับดึงข้อมูล) : Sql server , Postgres , Bigquery etc.
- Analyze Tools (ใช้สำหรับการวิเคราะห์ข้อมูลเบื้องต้น) : Excel , Spreadsheet etc.
- BI Tools (ใช้สำหรับวิเคราะห์ข้อมูลและนำเสนอ): Power BI , Tableau , Qwik etc.
ทั้ง 3 ประเภทที่กล่าวมา ล้วนใช้ Python ในการทำงานทดแทนได้ โดยสามารถเลือกใช้ Library ดังต่อไปนี้
SQLAlchemy/ Pyodbc / Pymysql จะมีความแตกต่างกับ Data Engineer ตรงที่ Data Analyst ใช้สำหรับเชื่อมต่อเพื่อดึงข้อมูลที่เราต้องการจาก Database (อันที่ Data Engineer จัดการไว้ให้เรียบร้อยแล้วนั่นแหละ) กรณีที่ต้องการเชื่อมต่อ Bigquery , RedShift บน Cloud Platform จะมี Library แยกออกไปโดยจะต้องมีการใส่ Credential file เพื่อยืนยันสิทธิ์ในการดึงข้อมูล เช่น Service account ที่มีสิทธิ์ในการ query database นั้น
Pandas / NumPy / Polar ใช้ในการจัดระเบียบข้อมูลที่มีลักษณะเป็น Table หรือต้องการเปลี่ยนแปลงค่าจากต้นทางให้อยู่ในรูปแบบของ Table ก็สามารถทำได้เช่นกัน นอกจากนั้นยังสามารถใช้ python ในการเปลี่ยนข้อมูลในคอลัมน์ตามเงื่อนไขที่เรากำหนดเองได้ มีความยากกว่าการเขียนสูตรใน Excel นิดเดียวเท่านั้น ถ้าเข้าใจวิธีการเขียนก็จะทำให้งานง่าย และเร็วขึ้น
Matplotlib / Seaborn ไลบรารีสำหรับสร้าง Data Visualization ที่หลากหลายและปรับแต่งได้ ตั้งแต่กราฟเส้น, กราฟแท่ง, ฮิสโตแกรม, สแคทเทอร์พลอต, ไปจนถึงแผนภูมิวงกลม มีอินเทอร์เฟซที่เรียบง่ายและเหมาะสำหรับการสร้างกราฟเชิงสถิติที่สวยงามและข้อมูลเชิงลึก เพื่อใช้ในการอ่านข้อมูลเบื้องต้น และใช้สำหรับการ Explora Data เพื่อค้นหา Business Insight สำคัญ

สรุปเนื้อหา
สำหรับงานสาย Data ภาษา Python จะทำให้เราสามารถทำงานใหญ่ได้ง่ายขึ้น มีข้อจำกัดเรื่องการประมวลผลลดลง และเร็วขึ้น แต่ละสายงานจะมีการใช้ที่เฉพาะเจาะจงไม่เหมือนกัน และความเข้าใจเรื่อง Library และ Algorithm ไม่เท่ากัน โดยทั่วไปแล้วก็ควรจะฝึกใช้ Pandas ให้คล่อง เพื่อจะต่อยอดไปทำงานอื่น ๆ ได้
สำหรับงานสาย Data มีข้อควรระวังที่สำคัญในการเลือกใช้ Tools ที่เหมาะสมเช่นกัน อย่าง Tableau , Excel ก็อาจจะทำงานบางอย่างได้ดีในแบบที่ python ไม่ได้สามารถทำได้ง่าย ดังนั้นเราจึงจะต้องเลือกวิธีการและลำดับขั้นตอนในการทำงานให้เหมาะสมกับงานของเรา และที่สำคัญเลือกให้เหมาะกับงบประมาณที่เราจะใช้ด้วยครับ
ข้อดีของภาษา Python
1. สามารถใช้ได้กับงานที่มีความหลากหลาย ตั้งแต่ทำแอพ เขียนเว็บ ตลอดจนทำข้อมูลขนาดใหญ่ และมี Open source project มากมายให้ศึกษา
2. Community ใหญ่ มี Library รับรองจำนวนมาก
3. เขียนง่ายที่สุดถ้าไม่นับ SQL กับ HTML ยากสุดสำหรับมือใหม่อาจจะเป็นแค่การเว้น Indent เท่านั้น แต่สามารถนี้โปรแกรมเขียนโค้ดมี AI ช่วยหมดแล้ว น่าจะทำงานได้ง่ายขึ้น
4.สามารถใช้งานได้ฟรีไม่มีค่า License
ข้อพิจารณาของภาษา Python
1. เนื่องจากเป็นภาษาแบบ Interpreter ทำให้ความเร็วจะช้าแบบ ภาษา complier ที่คอมพิวเตอร์สามารถอ่านได้เร็วกว่า
2. การเรียนรู้ Library เฉพาะทางบางตัว อาจจะต้องใช้ Learning Curve สูงหากไม่มีความรู้พื้นฐานด้านนั้นมาก่อน
3. Python ไม่ได้บังคับให้ระบุชนิดข้อมูล แต่สามารถใช้ Type Hinting เพื่อระบุชนิดข้อมูลที่คาดหวังได้ ฟีเจอร์นี้ช่วยให้โค้ด อ่านง่ายขึ้น และช่วยให้เครื่องมือต่างๆ ตรวจสอบความถูกต้องของชนิดข้อมูลขณะพัฒนาได้ดีขึ้น
นอกจากนี้ Python ยังนิยมใช้ในงานที่เรามักจะต้องทำเป็นประจำ (Routine) เราสามารถเปลี่ยนให้เป็นงานแบบ automate workflow ได้ง่าย แม้ว่าสมัยนี้เราจะมีการใช้ no code automation อย่าง n8n , make ที่จะช่วยให้งานเราง่ายขึ้นแล้ว แต่งานบางอย่างของเราอาจจะต้องการ custom เฉพาะจุด ที่เครื่องมือเหล่านั้นอาจจะยังไม่สามารถทดแทน python ได้ 100%
สุดท้ายการเลือกใช้ Tools , Programming language ในการทำงานใด ๆ เราควรคำนึงถึง overhead cost ที่เราจะต้องเสียไปว่ามันคุ้มค่ากับเราในระยะยาวมากน้อยเพียงไหน
*ช่องแนะนำเกี่ยวกับการเขียน Python ขั้นพื้นฐาน โดย Mike lopster สอนได้เข้าใจง่ายสุด ลองไปฟังกันดู และลองทำตามก็ได้ครับ สำหรับมือใหม่
หรือถ้าใครเป็นสายอ่านสามารถดูได้ตามนี้เลยครับ https://docs.mikelopster.dev/c/python-series/101/intro