Vector search แบบง่าย ๆ จนงง
Vector Search ช่วยให้การค้นหาฉลาดขึ้น เข้าใจบริบทที่เราคิด ทำให้ได้คำตอบที่ตรงกว่า และมีประโยชน์มากขึ้นกว่าเดิม

เมื่อก่อนเวลาที่เราค้นหาอะไรสักอย่างในฐานข้อมูล หรือแม้กระทั่งในไฟล์ excel ที่หลาย ๆ คนใช้ในการทำงาน จะเป็นวิธีการค้นหาแบบทั่วไป โดยมีการใช้เครื่องหมายเป็นตัวบ่งชี้ในการดึงข้อมูลที่ตรงเงื่อนไขออกมา
วิธีการค้นหาในรูปแบบต่าง ๆ
หากเราต้องการค้นหาคำว่า นายก ถ้าเราใช้วิธีการค้นหาแบบตรงตัว EQUAL TO หรือ EXTRACT MATCH ผลลัพธ์ที่ได้ก็คือเราจะได้เฉพาะข้อมูลแถวที่มีคำว่า นายก เท่านั้นซึ่งก็อาจจะถูกต้องในแง่ของการใช้งานพื้นฐานทั่วไป ที่ไม่ได้ซับซ้อนมากนัก
หากเราต้องการค้นหา ข้อมูลที่มีคำว่า นายกอยู่ในนั้น ไม่ว่าจะอยู่ส่วนใดก็ตามของข้อความ เราก็สามารถใช้ LIKE หรือ CONTAINS เพื่อดึงข้อความนั้นออกมา เราอาจจะได้ข้อความที่มีคำว่า นายก, นายกรัฐมนตรี, นครนายก ซึ่งอาจจะเป็นคำที่มีบริบทแตกต่างกันออกไป
ยากขึ้นไปหน่อยจะก็ใช้ Pattern search แบบการใช้ Regular Expression ในการค้นหา เช่น ต้องการค้นหาคำว่า นายก เราอาจจะใช้ syntax เป็น ^นายก เพื่อให้แสดงข้อมูลเฉพาะข้อความที่ขึ้นต้นด้วยคำว่า นายก เท่านั้น ฉะนั้นเราจะไม่เจอคำว่า นครนายก, พ่อนายก, อดีตนายก
แต่เราก็อาจจะเจอคำอื่นที่ไม่เกี่ยวข้องอยู่ดี เช่น นายกรณ์ หรือบางครั้งเราอาจจะต้องการค้นหาคำที่เกี่ยวข้องอย่าง อดีตนายก ด้วยเช่นกัน แต่ดันไม่เข้าเงื่อนไขของ Regular Expression จะแก้ก็มีเงื่อนไขเต็มไปหมด ไม่หยืดยุ่นเหมือนกับเราเลือกเอง
แต่ถ้าสมมติเราต้องการค้นหาคำว่า นายก แล้วมีคำที่บริบทใกล้เคียงกันออกมา เช่น นายกรัฐมนตรี , ประธานาธิบดี , หัวหน้า เราสามารถทำได้โดยการใช้ vector search ครับ
Vector Search คืออะไร
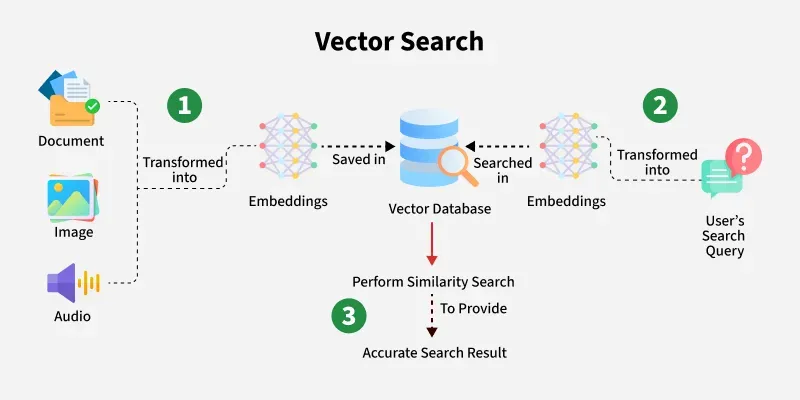
Vector search (การค้นหาแบบเวกเตอร์) คือวิธีการค้นหาโดยใช้คณิตศาสตร์ในการคำนวณความใกล้-ไกล ของชุดตัวเลขที่ถูกแปลงจากข้อความนั้น โดยขั้นตอนแรก ๆ ของการทำข้อมูลเวกเตอร์ เราจะต้องนำข้อความที่เราต้องการไปใช้ในการ embedding ด้วย AI เพื่อให้ข้อความเหล่านั้นอยู่ในรูปแบบของ Vector (ชุดตัวเลข) ซึ่งปัจจุบันมีผู้ให้บริการหลายเจ้าทั้ง Open AI , Gemini , Claude เป็นต้น และมีมิติของข้อมูลตั้งแต่ 384 - 3072 จุด ในการแสดงผลชุดตัวเลข
อธิบายเพิ่มเติมเกี่ยวกับหัวข้อ Vector นิดนึงครับ ใครที่เกลียดคณิตศาสตร์ผมจะพยายามยกตัวอย่างให้ง่ายที่สุด ส่วนใครที่เก่งคณิตศาสตร์อยู่แล้วคุณจะอ่านแล้วเข้าใจทันทีเลย
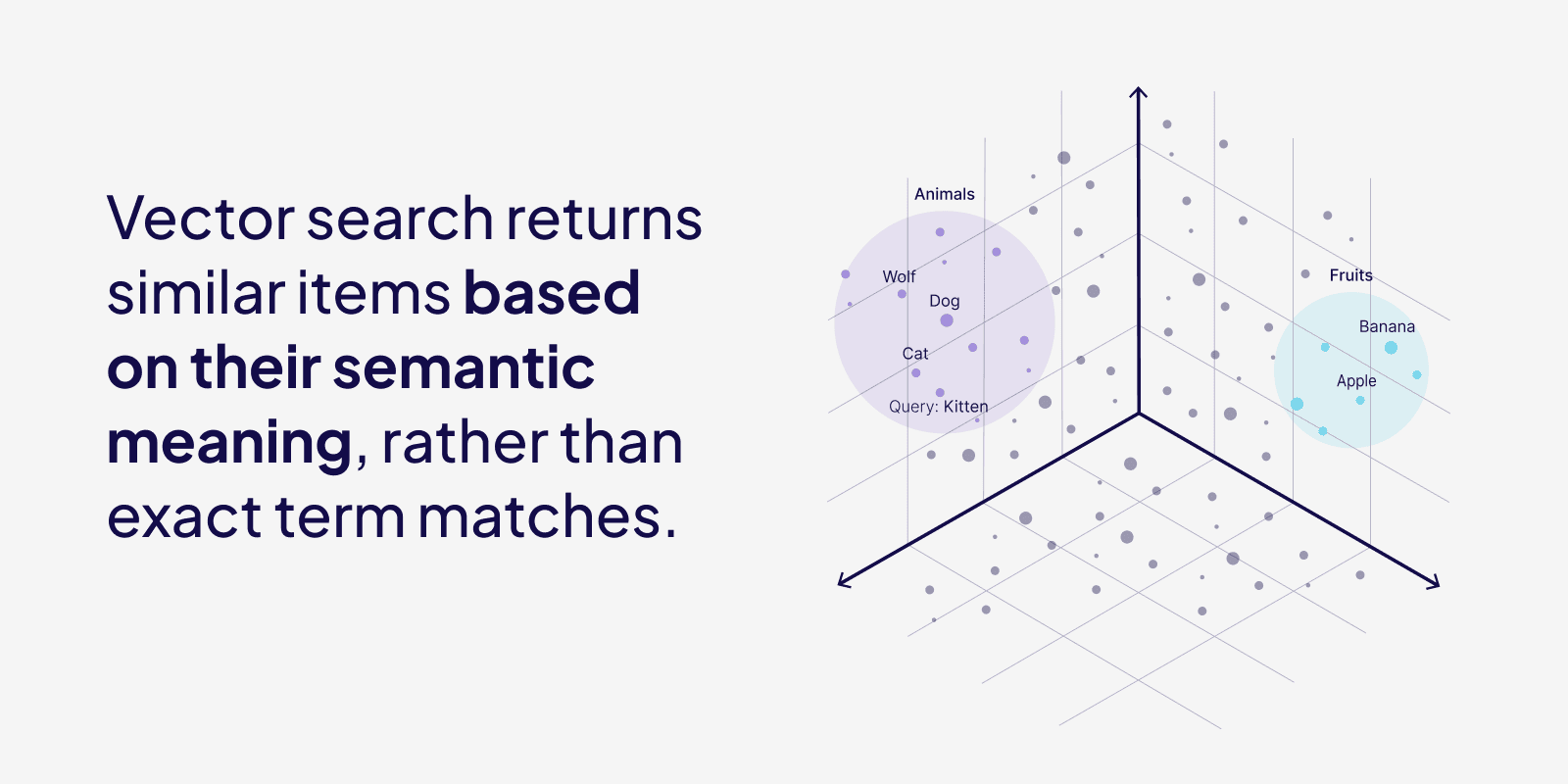
ลองคิดว่าเรามีคำว่า แมว AI จะไม่เข้าใจคำว่า แมว โดยตรง แต่มันจะเปลี่ยนคำนี้ให้กลายเป็น ชุดตัวเลข เช่น
แมว → [0.12, 0.98, -0.33, 0.55, ...]
หมา → [0.15, 1.01, -0.31, 0.52, ...]
แอปเปิ้ล → [-0.88, 0.10, 0.65, 0.04, ...]
ดูเผิน ๆ เหมือนเลขมั่ว ๆ ไม่มีความหมายอะไร แต่จริง ๆ แล้วแต่ละตัวเลขในชุดนั้น แทนความหมายบางด้านของคำ เช่น
ด้านที่ 1 อาจเกี่ยวกับ “สิ่งมีชีวิต”
ด้านที่ 2 เกี่ยวกับ “สัตว์เลี้ยง”
ด้านที่ 3 เกี่ยวกับ “สิ่งของ”
ฯลฯ
เมื่อทุกคำกลายเป็นกลุ่มตัวเลข เราก็สามารถวัดว่า สองคำอยู่ใกล้กันแค่ไหน ด้วยสูตรทางคณิตศาสตร์ เช่น cosine similarity คือวิธีวัดมุมระหว่างเวกเตอร์ เพื่อดูว่าคำสองคำมีทิศทางใกล้กันแค่ไหน
ดังนั้นถ้าคำสองคำมี vector ที่อยู่ใกล้กัน ก็หมายความว่าทั้งสอง มีความหมายใกล้กัน เช่น
แมว และ หมา -> อยู่ใกล้กันมาก
แมว และ แอปเปิ้ล -> อยู่ห่างกัน
Vector Search ทำยังไงได้ง่ายที่สุด
เมื่อเรารู้วิธีการทำงานของ vector search แล้ว ตอนนี้เราจะมาเริ่มทำ Vector search กันเถอะ ในวันนี้ผมจะแนะนำวิธีทำแบบที่ไม่ต้องเขียนโค้ดเลย แม้แต่บรรทัดเดียวครับ
โดยเราจะมีสิ่งที่ต้องเตรียมดังต่อไปนี้
1. Google Ai Studio Key ( เลือกใช้โมเดล Google gemini embedding 001)
2. Database ที่มีความสามารถใช้ feature Vector search ได้ เช่น MongoDb , PostgresQL ซึ่งกรณีนี้เราจะยกตัวอย่างผ่าน Postgresql เพื่อความง่ายของข้อมูล
3. n8n ใช้สำหรับการสร้าง workflow การทำงานแบบง่าย ๆ (ใช้ได้ทั้งเวอร์ชั่น Self host และ Cloud hosting)
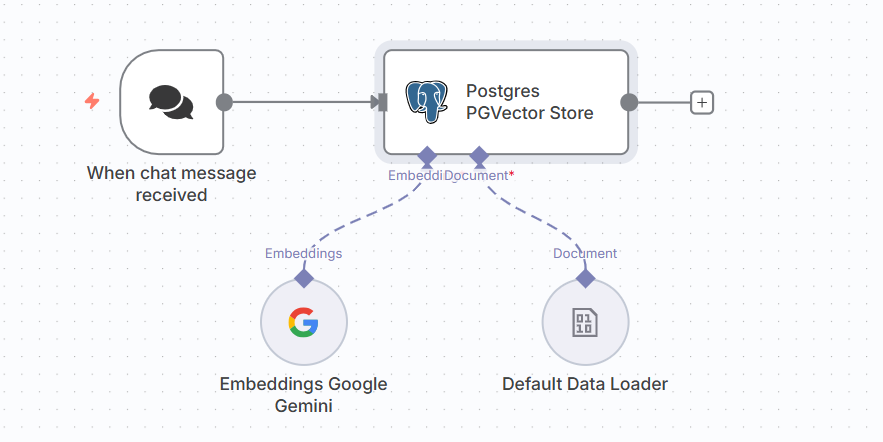
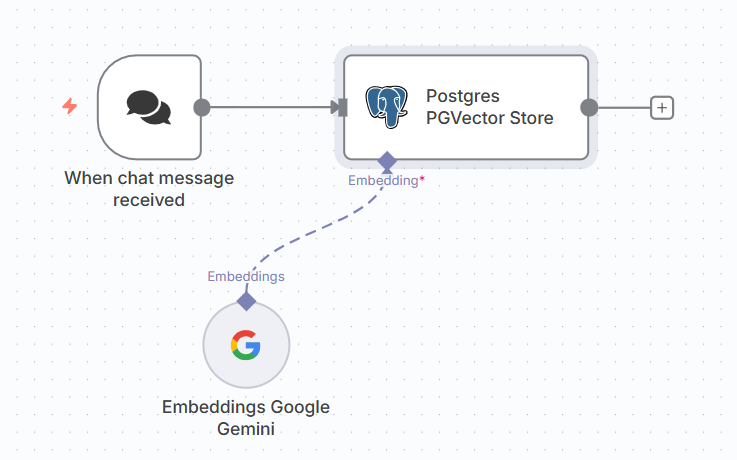
ภาพตัวอย่างแสดงให้เห็นวิธีการทำ PgVector Store เพื่อเก็บข้อมูลจาก Chat message
(จริง ๆ คุณอาจจะดึงข้อมูลจาก Database มาใช้แทน Chat message ได้นะครับ ผมยกตัวอย่างให้ดูง่ายเฉย ๆ )
นำมา Embedding เพื่อให้ได้ชุดตัวเลขของ Vector ลงในฐานข้อมูล สำหรับการใช้ในการค้นหา ในขั้นตอนนี้เราจะใช้ Operation Mode เป็น Insert Documents ลงบน Table ใน Postgresql
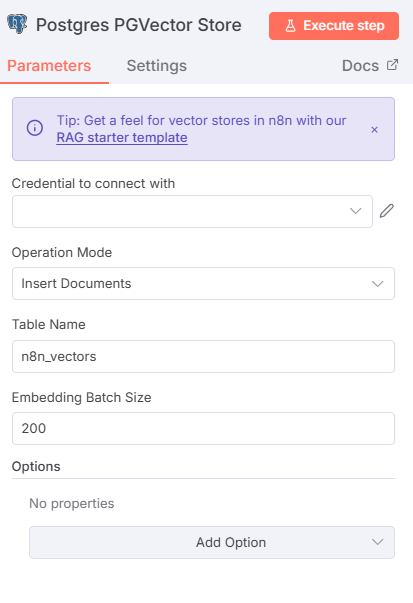
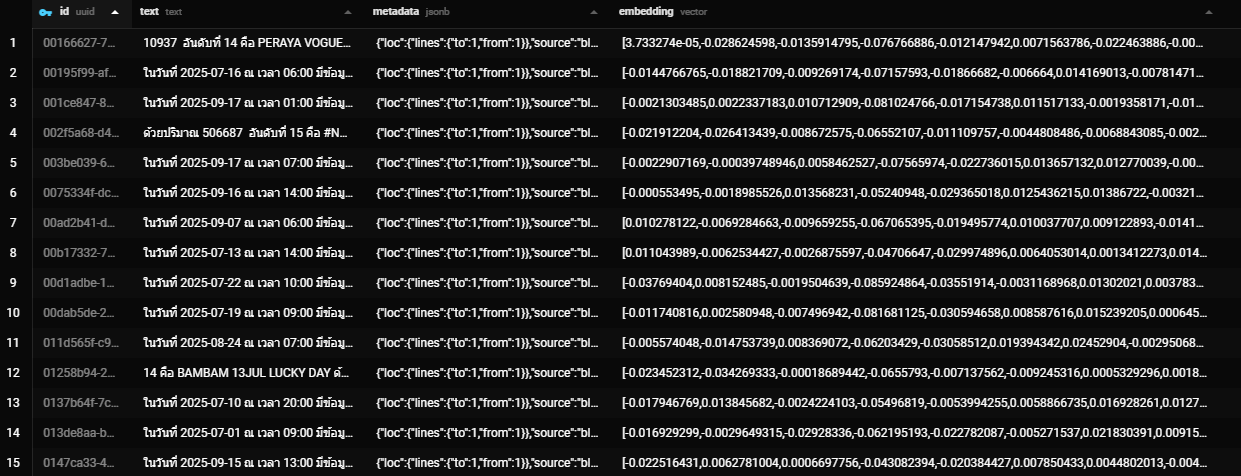
ตัวอย่างที่ถูกบันทึกลงใน Table Postgresql เราสามารถเก็บทั้ง uuid , text , metadata , embedding (ใช้สำหรับการค้นหา vector)
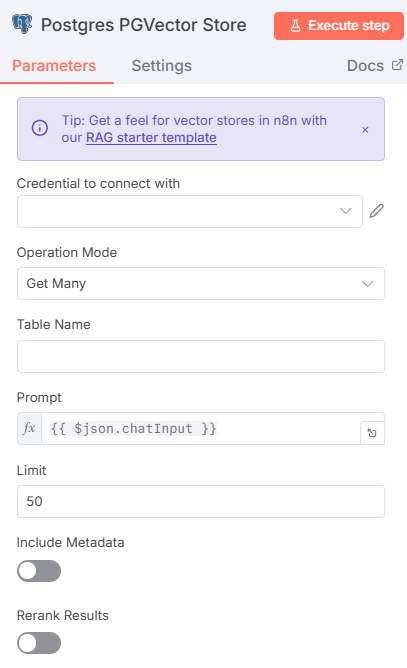
ส่วนวิธีการเรียกใช้เราสามารถทำได้ในรูปแบบคล้ายๆ กัน แต่เราจะเปลี่ยน Operation Mode เป็น Get Many เพื่อดึงข้อมูลที่มีความใกล้เคียงกันจากการเปรียบเทียบข้อมูล Vector หลังจากที่ Google Gemini Embedding ข้อมูลมาให้แล้ว
ประโยชน์และการนำไปใช้ของ Vector Search
ประโยชน์ของ vector search
- การค้นหาแบบ เข้าใจความบริบท ไม่ใช่แค่คำตรงตัว ทำให้ค้นหาได้แม้ไม่ตรงกับข้อความจริง เช่น ค้นหาคำว่า รถยนต์ไฟฟ้า ก็อาจจะเจอ tesla , EV , พลังงานสะอาด
- ผลลัพธ์แม่นยำและเป็นธรรมชาติมากขึ้น แทนที่จะต้องจำ keyword เป๊ะ ๆ สามารถค้นหาคำถามยาว ๆ หรือประโยคที่ไม่เป็นทางการ แต่บริบทเดียวกันได้
- ใช้ได้กับข้อมูลหลายประเภท การทำ vector ไม่ได้จำกัดแค่ข้อความเท่านั้น เราสามารถใช้กับ ภาพ เสียง วิดีโอ ได้เช่นกัน แต่อาจจะมีขั้นตอนที่ยากกว่า
- ทำงานร่วมกับ AI chat / ระบบ Recommendation ได้ดี Vector search เป็นหัวใจของระบบ Retrieval-Augmented Generation (RAG) ที่ AI สมัยใหม่นิยมใช้ในการค้นหาข้อมูลเพื่อตอบคำถามผู้ใช้งาน
- เหมาะกับฐานข้อมูลขนาดใหญ่ที่มีความซับซ้อน สามารถค้นหาเนื้อที่คล้ายกันได้โดยระยะเวลาสั้น แม้ว่าจะมีข้อมูลขนาดใหญ่ก็ตาม เนื่องจากใช้เทคนิค Approximate Nearest Neighbor (ANN) ทำให้เร็วและประหยัดทรัพยากร
การนำ Vector Search ไปใช้
Use case 1 : เราสามารถใช้สำหรับค้นหาสิ่งเหมือนกัน / มีความหมายคล้ายกัน / มีบริบทคล้ายกัน
หลายครั้งที่ผู้ใช้งานพิมพ์คำค้นไม่ตรงกับคำที่อยู่ในระบบ เช่น
- พิมพ์ผิดเล็กน้อย
- ใช้คำพ้อง หรือคำเรียกที่ต่างกัน
- จำชื่อเต็มของสิ่งที่ต้องการไม่ได้
ด้วยการค้นหาแบบทั่วไป (เช่น LIKE หรือ CONTAINS) ระบบจะดึงเฉพาะข้อความที่ “มีคำนั้นอยู่จริง ๆ” เท่านั้น
แต่ด้วย Vector Search ระบบสามารถ “เข้าใจความหมาย” และค้นหาข้อความที่ “ใกล้เคียงในบริบท” ได้ แม้จะไม่ตรงตัวเลยก็ตาม
Use case 2 : เราสามารถใช้ Vector search ไปต่อยอดกับการทำ RAG ได้ เช่นการทำแชทบอทถามตอบคำถาม
ปกติแล้ว AI Chatbot จะตอบคำถามจากสิ่งที่โมเดลรู้ (ข้อมูลที่ถูกเทรนไว้ก่อนหน้า) ซึ่งอาจไม่อัปเดต หรือไม่รู้ข้อมูลเฉพาะขององค์กร เช่น เอกสารภายใน รายงานสินค้า คู่มือใช้งาน ฯลฯ
แต่เมื่อเรานำ Vector Search มาทำงานร่วมกับ RAG (Retrieval-Augmented Generation) จะช่วยให้แชทบอท “ค้นข้อมูลจริงก่อนตอบ” ได้อย่างแม่นยำขึ้น
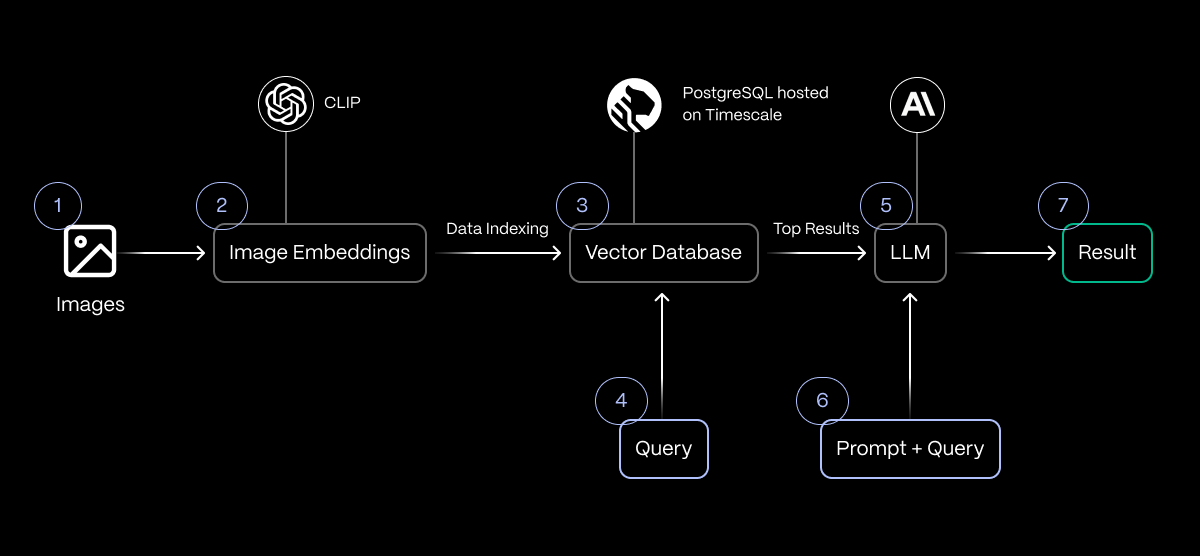
ข้อควรระวัง
- เมื่อเราใช้งาน embedding ด้วยโมเดลได้ก็ตาม เราจะต้องใช้ตัวนั้นสำหรับการค้นหา vector เดียว เพราะใช้โมเดลคนละตัวกัน จะมีความแม่นยำน้อยลง
- การเลือกใช้งาน model embedding ควรจะใช้งาน model ที่ใช้หลายภาษาได้ กรณีที่ข้อมูลที่เราต้องการให้ค้นหามีทั้งภาษาไทย และภาษาอังกฤษ ง่ายสุดคือใช้ gemini-embedding-001 ของ Google สามารถใช้ผ่าน Key ของ Google AI Studio ได้
- หากข้อมูลมีจำนวนมาก แนะนำให้จัดข้อมูลให้อยู่ในรูปแบบพร้อมใช้งาน แล้วไปทำเป็น batch เพื่อลดค่า API embedding จะสามารถลดค่าใช้จ่ายได้ดีกว่า