10 เรื่องที่ควรรู้ก่อนใช้ AI ในปี 2025
บทความเกี่ยวกับ 10 เรื่องที่คุณควรรู้ก่อนจะเสียเงินใช้ AI เพื่อให้การใช้ AI มีประสิทธิภาพและคุ้มค่าที่สุด

AI หรือ Artificial intellegent ที่เราใช้งานกันอย่างแพร่หลายในปีนี้ จริงๆ แล้วถูกพัฒนามาอย่างต่อเนื่อง หลายคนอาจจะเคยใช้ Chat GPT , Gemini , Claude หรือตัวอื่นๆ มาบ้างแล้ว แต่วันนี้เราจะมารู้จัก 10 เรื่องที่เราควรรู้เกี่ยวกับการใช้ AI
1. ประเภทของ AI (AI Types)
AI ไม่ได้มีแค่แบบเดียว แต่สามารถแบ่งออกได้หลายประเภท เช่น
ANI (Artificial Narrow Intelligence) หรือ AI แบบแคบ/เฉพาะด้าน
- เป็น AI ที่เราใช้กันอยู่จริงในปัจจุบัน
- ทำงานเก่งใน “งานเฉพาะทาง” เช่น Chatbot, ระบบแนะนำหนังใน Netflix, ระบบตรวจจับใบหน้า
- จุดอ่อนคือ ไม่สามารถทำงานนอกเหนือจากที่ถูกฝึกได้ เช่น AI เล่นหมากรุก เก่งแค่หมากรุก แต่ไม่สามารถทำอาหาร
AGI (Artificial General Intelligence) หรือ AI ระดับปัญญาทั่วไป
- เป็น AI ที่สามารถทำงานได้หลากหลายด้านเหมือนมนุษย์
- สามารถเรียนรู้ ทักษะใหม่ๆ และปรับตัวเข้ากับสถานการณ์ต่างๆ ได้
- ยังเป็น “เป้าหมายในอนาคต” ของวงการ AI ตอนนี้ยังไม่มี AGI ที่แท้จริง
ASI (Artificial Super Intelligence) หรือ AI เหนือกว่ามนุษย์
- เป็น AI สมมุติในอนาคต ที่มีความสามารถทางสติปัญญาเหนือกว่ามนุษย์ทุกด้าน
- สามารถคิด วิเคราะห์ และตัดสินใจได้เร็วกว่ามนุษย์มหาศาล
- มีการถกเถียงว่า ถ้าเกิดขึ้นจริงจะสร้างประโยชน์อย่างมาก หรืออาจเป็นความเสี่ยงต่อมนุษยชาติ
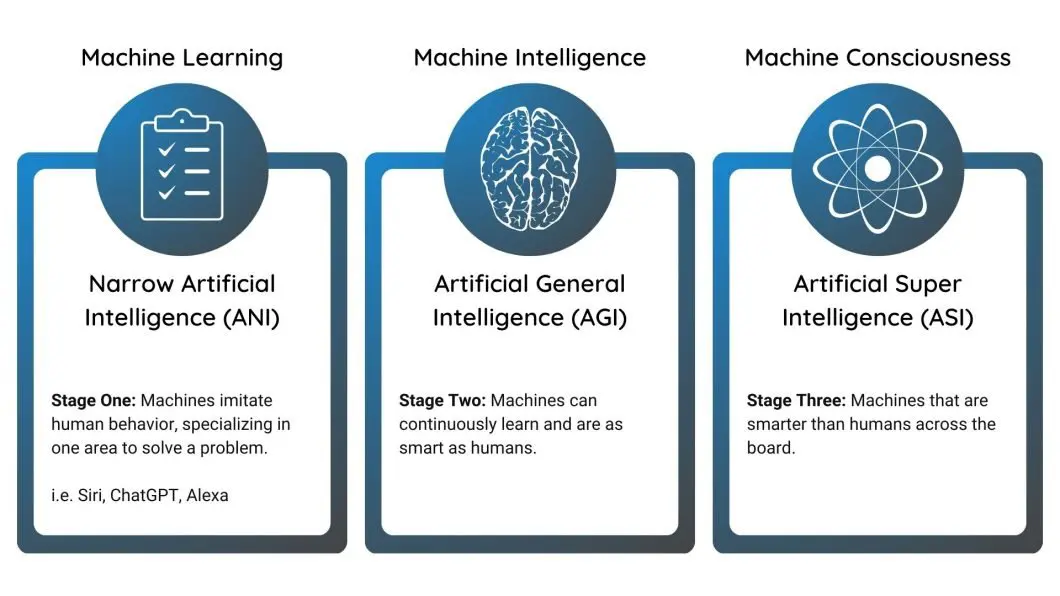
การเข้าใจประเภทเหล่านี้จะช่วยให้เราเลือกใช้เครื่องมือ AI ได้ถูกต้องตามเป้าหมาย
2. ขอบเขตความรู้และความผิดพลาดของ AI
แม้ว่า AI โดยเฉพาะ Generative AI ในปัจจุบัน จะมีความสามารถในการสร้างสรรค์และตอบคำถามได้อย่างน่าทึ่ง จนบางครั้งทำให้เรารู้สึกว่ามัน "ฉลาดรอบรู้" แต่ในความเป็นจริงแล้ว ความรู้ของ AI นั้นมีขอบเขตจำกัดและขึ้นอยู่กับปัจจัยหลายประการอย่างเคร่งครัด
ข้อจำกัดด้านข้อมูลและการอัปเดต: ความรู้ของ AI ไม่ได้มาจากความเข้าใจโลกแบบมนุษย์ แต่มาจากการเรียนรู้จาก "ข้อมูลที่ใช้ในการฝึกฝน" (Training Data) เท่านั้น หากข้อมูลที่ใช้ฝึกมีข้อจำกัดด้านปริมาณ คุณภาพ ความหลากหลาย หรือความทันสมัย ความรู้ของ AI ก็จะมีข้อจำกัดตามไปด้วย ตัวอย่างเช่น AI อาจไม่มีข้อมูลเหตุการณ์ล่าสุดที่เพิ่งเกิดขึ้น หากฐานข้อมูลของมันไม่ได้ถูกอัปเดตให้ครอบคลุมถึงปัจจุบัน หรือบางระบบอาจไม่สามารถเข้าถึงข้อมูลใหม่ๆ ได้แบบเรียลไทม์ เว้นแต่จะถูกออกแบบมาให้เชื่อมต่อกับแหล่งข้อมูลปัจจุบัน เช่น การค้นหาผ่านเว็บ (Web Search) หรือฐานข้อมูลเฉพาะทางต่างๆ ดังนั้น การมองว่า AI เป็นเสมือน "สารานุกรมที่สมบูรณ์แบบ" จึงเป็นความเข้าใจที่คลาดเคลื่อน
ปัญหาการ "แต่งเรื่อง" หรือ Hallucination: หนึ่งในข้อควรระวังที่สำคัญที่สุดเมื่อใช้งาน AI คือปรากฏการณ์ที่เรียกว่า "Hallucination" ซึ่งหมายถึงการที่ AI สร้างข้อมูลที่ดูเหมือนจริง แต่ในความเป็นจริงแล้วเป็นข้อมูลที่ไม่มีอยู่จริง ไม่เป็นความจริง หรือไม่ถูกต้อง ตัวอย่างเช่น AI อาจ:
- สร้างข้อมูลเท็จ: ประดิษฐ์ข้อเท็จจริงหรือเหตุการณ์ที่ไม่เคยเกิดขึ้น
- อ้างอิงแหล่งข้อมูลปลอม: ระบุชื่อหนังสือ เว็บไซต์ หรือบุคคลอ้างอิงที่ไม่เคยมีอยู่จริง หรือบิดเบือนการอ้างอิงที่มีอยู่
- แต่งตัวเลขหรือสถิติขึ้นมาเอง: นำเสนอตัวเลขหรือสถิติที่ไม่มีหลักฐานรองรับ
ปรากฏการณ์ Hallucination เกิดขึ้นได้จากหลายสาเหตุ เช่น ข้อจำกัดของโมเดลในการทำความเข้าใจบริบทอย่างลึกซึ้ง, ความไม่สมบูรณ์ของข้อมูลที่ใช้ฝึก, หรือการที่โมเดลพยายาม "คาดเดา" คำตอบเมื่อไม่มั่นใจ เพื่อให้ได้ผลลัพธ์ที่ฟังดูสมเหตุสมผล

ความจำเป็นในการตรวจสอบความถูกต้อง: ด้วยเหตุนี้ ผู้ใช้งานจึงมีความจำเป็นอย่างยิ่งที่จะต้อง "ตรวจสอบความถูกต้องของข้อมูลทุกครั้ง" ที่ได้รับจาก AI โดยเฉพาะอย่างยิ่งเมื่อนำข้อมูลเหล่านั้นไปใช้ในงานที่มีความสำคัญสูง เช่น:
- งานวิจัยและวิชาการ: การอ้างอิงแหล่งข้อมูลผิดพลาดหรือใช้ข้อมูลเท็จอาจส่งผลร้ายแรงต่อความน่าเชื่อถือของงาน
- การตลาดและการสื่อสาร: ข้อมูลที่ไม่ถูกต้องอาจสร้างความเข้าใจผิดและทำลายภาพลักษณ์ของแบรนด์
- การตัดสินใจทางธุรกิจ: การตัดสินใจบนพื้นฐานของข้อมูล Hallucination อาจนำไปสู่ความเสียหายทางการเงินหรือโอกาสทางธุรกิจที่สูญเสียไป
- งานข่าวและข้อมูลสาธารณะ: การเผยแพร่ข้อมูลที่ไม่จริงอาจสร้างความสับสนและผลกระทบในวงกว้าง
การใช้งาน AI อย่างมีสติและรู้เท่าทันข้อจำกัดของมัน จะช่วยให้เราใช้ประโยชน์จาก AI ได้อย่างเต็มที่ โดยลดความเสี่ยงจากความผิดพลาดที่อาจเกิดขึ้น และรักษาระดับความน่าเชื่อถือของข้อมูลที่เรานำเสนอหรือนำไปใช้ประโยชน์
3. วิธีการทำงานของ AI (เบื้องต้น)
AI ไม่ได้มีความคิดหรืออารมณ์เหมือนมนุษย์ แต่ทำงานผ่านการ เรียนรู้จากข้อมูลจำนวนมหาศาล โดยใช้ คณิตศาสตร์และสถิติ มาช่วยวิเคราะห์ความสัมพันธ์ของข้อมูล เช่น การเดาคำถัดไปในประโยค หรือการทำนายภาพที่ใกล้เคียงที่สุด
การเรียนรู้ด้วยคณิตศาสตร์ (Mathematical Learning)
- ข้อมูลที่ป้อนให้ AI จะถูกเปลี่ยนเป็น ตัวเลข (Vector / Matrix)
- AI จะใช้สมการคณิตศาสตร์ เช่น การคูณเมทริกซ์, การหาค่าเฉลี่ยถ่วงน้ำหนัก (Weighted Average), ฟังก์ชัน Activation เพื่อหาความสัมพันธ์
- กระบวนการนี้จะเกิดขึ้นเป็น “เลเยอร์” หลายชั้นในสิ่งที่เรียกว่า Neural Network ทำให้ AI สามารถจับรูปแบบที่ซับซ้อนได้
การเทรนโมเดล (Training)
ก่อนที่ AI อย่าง ChatGPT หรือ MidJourney จะถูกใช้งานได้จริง ต้องผ่านการ เทรน (Train) ด้วยข้อมูลจำนวนมหาศาล เช่น หนังสือ บทความ โค้ด หรือรูปภาพ
- ขั้นตอนการเทรน: AI จะลองเดาผลลัพธ์ (เช่น เดาคำถัดไป) → เปรียบเทียบกับคำตอบจริง → คำนวณ “ความผิดพลาด” (Loss) → ปรับค่าพารามิเตอร์ภายในโมเดลด้วยวิธีการคณิตศาสตร์ที่เรียกว่า Gradient Descent
- กระบวนการนี้จะทำซ้ำหลายล้านครั้ง จนโมเดล “เรียนรู้รูปแบบ” ได้ดี
เมื่อผู้ใช้ทั่วไปได้ใช้งาน
AI ที่เราใช้อยู่ทุกวันนี้ เช่น ChatGPT ผ่านการเทรนล่วงหน้าแล้ว (Pre-trained) ดังนั้นเวลาผู้ใช้ส่งข้อความเข้าไป AI จะไม่ “เรียนรู้ใหม่ตั้งแต่ต้น” แต่จะ ใช้ความรู้ที่ถูกฝึกมาแล้วมาทำนายผลลัพธ์แบบเรียลไทม์
นั่นหมายความว่า สิ่งที่เราเห็นเหมือนการ “คิด” ของ AI แท้จริงแล้วคือ การจับรูปแบบ (Pattern Recognition) ตามคณิตศาสตร์ ไม่ใช่การใช้เหตุผลเชิงตรรกะเหมือนสมองมนุษย์
4. Tokenization, ค่าใช้จ่าย และประสิทธิภาพ
ก่อนที่ AI จะเข้าใจข้อความ ข้อมูลที่เราป้อนเข้าไปจะถูก “ตัด” ออกเป็นหน่วยเล็กๆ ที่เรียกว่า โทเค็น (Token) ซึ่งอาจเป็นคำหรือแม้กระทั่งส่วนหนึ่งของคำ เช่นคำว่า Artificial อาจถูกตัดออกเป็น Artifi + cial

ทำไมโทเค็นถึงสำคัญ?
- มีผลต่อค่าใช้จ่าย
- ผู้ให้บริการ AI ส่วนใหญ่คิดค่าบริการตามจำนวนโทเค็นที่ใช้ (ทั้ง Input และ Output)
- ยิ่งข้อความยาว = ใช้โทเค็นมากขึ้น = ค่าใช้จ่ายสูงขึ้น
- มีผลต่อความยาวที่ AI รองรับได้
- แต่ละโมเดลมี Context Window จำกัด เช่น 4,000, 32,000 หรือ 1,000,000 โทเค็น ขึ้นอยู่กับผู้ให้บริการเป็นคนกำหนด
- ถ้าเกินกว่านี้ AI จะ “ลืม” หรือไม่สามารถประมวลผลได้
- เกี่ยวข้องกับประสิทธิภาพการทำงาน
- การสร้างข้อความสั้นๆ ใช้พลังงานต่ำ และสามารถทำงานในรูปแบบ Batch ได้
- แต่การสร้าง ภาพ เสียง หรือวิดีโอ ใช้ทรัพยากรมากกว่าอย่างมหาศาล เช่น GPU ประสิทธิภาพสูงและเซิร์ฟเวอร์ขนาดใหญ่
สิ่งที่ควรรู้ก่อนใช้งาน
- ยิ่งข้อความหรือ Prompt ยาว → ยิ่งเสียค่าใช้จ่าย
- การสร้างสื่อที่ซับซ้อน (ภาพ/วิดีโอ/เสียง) → ใช้ทรัพยากรมากกว่าข้อความ
- การออกแบบ Prompt และ Context อย่างมีประสิทธิภาพ (เขียนให้สั้นแต่ครบถ้วน) → ช่วยลดทั้ง ต้นทุน และ เวลาในการประมวลผล
5. Prompt Engineer vs Context Engineer
เวลาคนส่วนใหญ่พูดถึงการใช้ AI มักจะนึกถึงคำว่า Prompt Engineer ซึ่งคือการออกแบบคำสั่ง (Prompt) ให้ AI ตอบได้ตามที่เราต้องการ เช่น การใช้คำสั่งชัดเจน มีตัวอย่างประกอบ หรือการใส่เงื่อนไขต่างๆ เพื่อควบคุมผลลัพธ์
แต่ปัจจุบันเริ่มมีอีกแนวคิดหนึ่งที่เรียกว่า Context Engineer ซึ่งไม่ได้โฟกัสแค่ “เขียน Prompt ดีๆ” แต่เน้นไปที่ การจัดการข้อมูลและบริบท (Context) ที่ป้อนให้ AI เช่น
- เลือกว่าจะใส่ข้อมูล Background อะไร
- จัดลำดับความสำคัญของข้อมูลอย่างไร
- ตัดสิ่งที่ไม่จำเป็นออกเพื่อไม่ให้ AI สับสน
สำหรับผมผู้ไม่เคยเชื่อใน Prompt Engineer ในการใช้ AI มาก่อน การเขียน Prompt จริงๆแล้วผมมองว่ามันขึ้นอยู่กับบุคคลมากกว่า ผมค่อนข้างเชื่อว่าถ้าเราใส่บริบท ( Context) เข้าไปในคำสั่งได้ มันอาจจะช่วยให้เราได้คำตอบที่ถูกต้องมากกว่า และแก้ปัญหาได้เร็วขึ้น
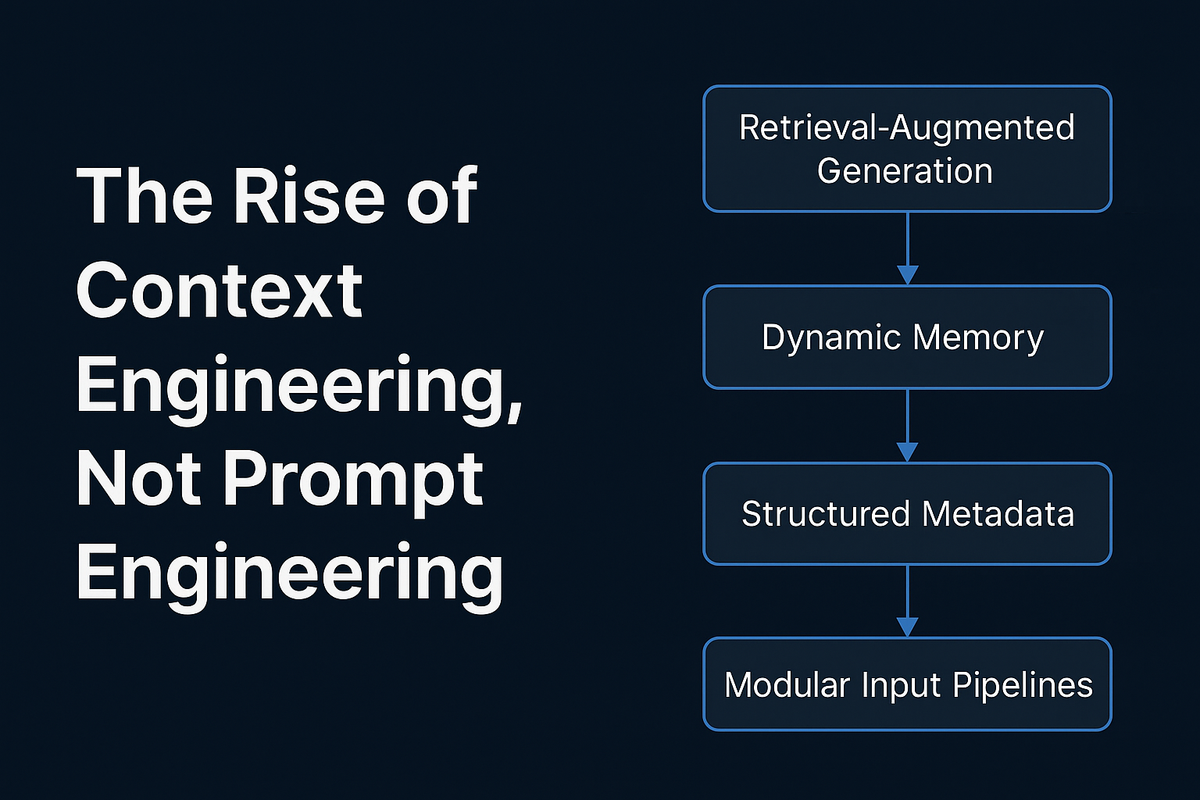
สรุปง่ายๆ:
- Prompt Engineer = ศิลปะการเขียนคำสั่งให้ฉลาด
- Context Engineer = ศิลปะการออกแบบข้อมูลและบริบทที่ AI ใช้ในการคิด
ทั้งสองอย่างต้องใช้ควบคู่กัน ถ้า Prompt ดีแต่ Context ไม่ชัดเจน AI ก็ยังตอบผิดได้ ในทางกลับกัน ถ้า Context ถูกออกแบบดี แม้ Prompt จะธรรมดา AI ก็สามารถให้คำตอบที่มีคุณภาพได้
6.ประเภทของความจำ (Memory Types)
ในวงการ AI ปัจจุบันมีการพูดถึง Memory ของโมเดล อยู่หลายแบบ ได้แก่:
Short-Term Context (ระยะสั้น)
- ความจำที่อยู่ใน Context Window ของโมเดลโดยตรง
- ใช้ได้เฉพาะในบทสนทนาปัจจุบัน
- ถ้าโทเค็นเกิน ระบบจะเริ่มลืม
Extended Memory (เสริมภายนอก)
- ใช้เครื่องมือหรือฐานข้อมูลช่วยเก็บข้อความการสนทนาแบบยาว เช่น การเก็บ log conversation ลงใน Redis, Postgres หรือ Vector Database (เช่น Pinecone, Weaviate, FAISS)
- จากนั้นจึงเลือกเฉพาะ “ข้อมูลที่เกี่ยวข้อง” มาเติมใน Prompt ใหม่ (เรียกว่า Retrieval-Augmented Generation – RAG)
Persistent / Long-Term Memory (ถาวร)
- ระบบสามารถ “จำ” ผู้ใช้งานข้ามเซสชันได้ เช่น จำ preference, สไตล์การเขียน หรือข้อมูลส่วนตัว
- ทำได้โดยเก็บ metadata และ content ในฐานข้อมูล แล้วดึงมาใช้ทุกครั้งที่ผู้ใช้กลับมา
Context Engineer ช่วยอย่างไร
Context Engineer คือผู้ที่ออกแบบว่า “ข้อมูลอะไรควรถูกใส่เข้าไปใน Prompt” เพื่อลดปัญหาความจำสั้นของ AI เช่น:
- เลือกตัดข้อความที่ไม่จำเป็นออก
- ดึงเฉพาะข้อมูลสำคัญจากฐานข้อมูลมาเติมใหม่
- ใช้เทคนิคอย่าง Summarization เพื่อลดความยาวของบทสนทนาโดยไม่เสียสาระ
ดังนั้น แม้โทเค็นจะเกิน Context Window ก็ยังสามารถ “จำได้” หากมีการออกแบบ Context และ Memory เสริมที่ดี
Automation Tools และ Memory จริงในปัจจุบัน
ตอนนี้เริ่มมีเครื่องมือที่ช่วยจัดการ Memory ให้กับ LLM โดยตรง เช่น
- LangChain / LlamaIndex → Framework ยอดนิยมที่ช่วยเชื่อม LLM เข้ากับฐานข้อมูล (Redis, Postgres, Vector DB) เพื่อทำ RAG
- Redis → ใช้เก็บข้อความสั้นๆ และ metadata เพื่อ recall เร็วมาก
- Postgres + pgvector → ใช้เก็บ embedding ของข้อความ ทำให้สามารถค้นหาความทรงจำที่ “ใกล้เคียง” กับสิ่งที่ผู้ใช้ถามใหม่ได้
- Pinecone, Weaviate → Vector Database สำหรับ memory ระยะยาวโดยเฉพาะ
พูดง่ายๆ ตอนนี้ Memory ของ AI ไม่ได้อยู่แค่ในโมเดล แต่เกิดจากการผสมผสานระหว่าง LLM + Database ภายนอก
👉 ดังนั้น ถ้าโทเค็นเกิน Context Window จริงๆ วิธีแก้ก็คือใช้ Context Engineering + External Memory (Redis, Postgres, Vector DB) เพื่อให้ AI “จำได้” มากกว่าที่โมเดลทำได้เอง
7. ความเป็นส่วนตัว (Privacy & Data Security)
การใช้ AI นั้น ต้องระมัดระวังเรื่องข้อมูลส่วนตัวและความลับ เพราะข้อมูลที่ป้อนเข้าโมเดลอาจถูกนำไปใช้ในการ ฝึกโมเดลต่อ หรือมีความเสี่ยงด้านความปลอดภัย
ข้อควรระวังสำหรับผู้ใช้งานทั่วไป
- ห้ามใส่ข้อมูลลับ/ข้อมูลสำคัญลง AI เช่น
- รหัสผ่าน
- เลขบัตรประชาชน
- ข้อมูลลูกค้า
- ข้อมูลเหล่านี้อาจถูก เก็บหรือใช้ซ้ำ เพื่อปรับปรุงโมเดล AI หากเราไม่แน่ใจเรื่องนโยบายความเป็นส่วนตัวของผู้ให้บริการ ให้เราลองตรวจสอบจากผู้ให้บริการอีกทีครับ หลายๆ เจ้ามีการรองรับเรื่อง Privacy เขียนไว้เรียบร้อยแล้ว
ข้อควรระวังสำหรับนักพัฒนา
- API Keys / Tokens / Secrets
- ไม่ควรใส่ตรงในโค้ด (hard-code) เพราะโค้ดอาจถูก push ขึ้น GitHub หรือแชร์โดยไม่ได้ตั้งใจ
- ควรใช้ Environment Variables (.env) หรือ Secret Manager ของ Cloud Provider เช่น AWS Secrets Manager, Google Secret Manager
- ตรวจสอบให้แน่ใจว่า log หรือ error message ไม่โชว์ token/secret
- การจัดการ Environment Variables
- .env ไม่ควรถูก commit ขึ้น repo สาธารณะ
- ใช้ไฟล์ตัวอย่าง
.env.exampleแทน และ document ว่าต้องใส่ค่าอะไรบ้าง - แยก dev / staging / production environment เพื่อจำกัดสิทธิ์การเข้าถึง
- การเข้าถึงข้อมูล AI / โมเดล
- หากเรียก LLM API, Generative AI API, หรือ Workflow Agent ผ่าน token
- อย่าใช้ token ของ production ใน dev/staging
- ระวังการเก็บ log ที่มี ข้อมูลผู้ใช้จริง พร้อม token
- การใช้ sandbox / mock API จะช่วยลดความเสี่ยงในการทดสอบ
- หากเรียก LLM API, Generative AI API, หรือ Workflow Agent ผ่าน token
เมื่อไม่นานมานี้มีข่าว claude code อ่านไฟล์ .env โดยอัตโนมัติ สำหรับนักพัฒนาที่ไม่ได้ตั้งค่า config อย่างถูกต้อง ทำให้เราต้องมาระวังเรื่องการใช้ AI ในการ Vibe Coding มากขึ้น
[Security] Claude Code reads .env files by default - This needs immediate attention from the team and awareness from devs
by u/sirnoex in ClaudeAI
การใช้งานในองค์กร/Enterprise
- องค์กรใหญ่ส่วนมากจะใช้ AI ที่มีระบบรักษาความเป็นส่วนตัวสูง เช่น:
- มี encryption ทั้งตอนส่งข้อมูลและเก็บข้อมูล
- ไม่เก็บข้อมูลลูกค้าในคลาวด์สาธารณะ
- ใช้ on-premise AI หรือ private cloud เพื่อป้องกันข้อมูลรั่วไหล
- ข้อจำกัดที่ควรรู้:
- แม้ระบบจะประกาศไม่เก็บข้อมูล แต่เราก็ไม่สามารถรู้ได้ 100% ว่าข้อมูลถูกนำไปใช้ที่ไหน
- บางบริการ Enterprise อาจจำกัดการใช้งานข้ามประเทศ (data residency) ทำให้บางฟีเจอร์/โมเดลอาจใช้ไม่ได้หากเซิร์ฟเวอร์อยู่ต่างประเทศ
คำแนะนำ
- ตรวจสอบ Privacy Policy และ Terms of Service ของผู้ให้บริการก่อนใช้งาน
- ใช้ AI on-premise หรือ private cloud หากต้องจัดการข้อมูลสำคัญขององค์กร
- สำหรับงานที่มีข้อมูลอ่อนไหวมาก เช่น การเงิน การแพทย์ หรือข้อมูลลูกค้า ควร ไม่ป้อนข้อมูลตรง ๆ ให้โมเดลออนไลน์ ให้ทำ anonymization / pseudonymization ก่อน
- สำหรับองค์กรที่ต้องปฏิบัติตาม
8. Workflow และ Agentic AI
- Workflow AI = เอา AI/LLM ไปอยู่ใน “กระบวนการทำงานอัตโนมัติ” ที่มีทริกเกอร์–แอ็กชัน–เอาท์พุตชัดเจน (เช่น อีเมลเข้า → สรุป → บันทึกลงชีต → แจ้ง Slack)
- Agentic AI = “ตัวแทน” ที่ตั้งเป้าหมายเอง วางแผน แบ่งงาน เรียกเครื่องมือ และทำงานหลายขั้นตอนแบบกึ่งอิสระ (รวมถึงให้เอเจนต์คุยกันเองได้)
เมื่อไหร่ใช้ Workflow / Agent
- งานซ้ำ ๆ โครงสร้างตายตัว → ใช้ Workflow
- งานซับซ้อน ต้องตัดสินใจหลายเงื่อนไข หรือแยกบทบาทเป็นหลาย “Assistant” → ใช้ Agentic AI
องค์ประกอบทั่วไปที่ใช้ในงาน
- Trigger (เหตุการณ์เริ่ม): อีเมลใหม่, ฟอร์มส่งเข้า, ไฟล์ลงโฟลเดอร์
- Orchestrator: n8n / Make / Agentspace กำกับลำดับขั้นตอน
- Tools/Connectors: Gmail, Sheets, Slack, CRM, คลังเอกสาร, เว็บสแครปเปอร์, ฟังก์ชันโค้ด
- LLM/Agents: เรียกใช้โมเดล (สรุป, จัดหมวด, แปลงรูปแบบ), หรือให้ “เอเจนต์” วางแผน–แบ่งงาน
- Memory / Grounding: เก็บบริบท, ค้นคืนความรู้ (RAG) จากเอกสาร/ฐานข้อมูล
- Outputs & Guardrails: ส่งผลลัพธ์, บันทึกล็อก, ตรวจนโยบาย/ความปลอดภัย
เครื่องมือหลัก + ตัวอย่างใช้งาน
A) n8n – Workflow Automation ที่ผสาน AI ได้ลึก
เหมาะกับทีมเทคนิค/สตาร์ทอัพที่อยากคุมโฮสต์เอง ปรับแต่งอิสระ เชื่อม LLM และระบบได้ลึก ๆ (มีทั้งแบบ self host , cloud )
- จุดเด่น: โอเพ่นซอร์ส/โฮสต์เองได้, ลาก-วาง, มีโหนด AI/LLM ให้พร้อม (เช่น OpenAI node, Agent node) และเชื่อมแอปยอดนิยมได้เยอะมาก (Gmail/Sheets/Slack/Notion ฯลฯ)
- ตัวอย่าง Workflow “สร้างคอนเทนต์จากถึงการโพสต์ลงโซเชียลมีเดีย”
- Trigger จาก Google Docs “บทความร่างใหม่”
- LLM สรุป TL;DR + ทำ Title ทางเลือก 5 แบบ
- LLM สร้าง Social caption 3 เวอร์ชัน
- ส่งอนุมัติใน Slack (ปุ่ม Approve/Reject)
- อนุมัติแล้วโพสต์อัตโนมัติ + บันทึกลง Google Sheets (URL/เวลา)
- ข้อควรคิด: ตั้ง rate limit API, ใส่ guardrails (เช่น คำต้องห้าม), และทำ logging/รีเทรซงาน
B) Make – Workflow/Integration เชิงธุรกิจ + AI Agents
เหมาะกับทีมธุรกิจที่ต้องการ UI ใช้ง่าย เครื่องมือเยอะ และอยากลอง “AI Agents” แบบรวดเร็ว โดยไม่อาศัยความรู้ด้าน IT (มีแบบเสียเงิน เท่านั้น ทดลองฟรี 7 วัน)
- จุดเด่น: สร้าง “Scenario” ด้วย drag-and-drop, เชื่อมต่อได้กว่า 2,000 แอป, โมดูล AI ครบ (OpenAI/Gemini/Whisper ฯลฯ) และมี Make AI Agents ให้สร้างเอเจนต์ใช้งานในธุรกิจ (อยู่บนแผนชำระเงิน)
- ตัวอย่าง “Sales Triage Agent”:
- Trigger: ฟอร์มลูกค้าจากเว็บ → Agent จัดกลุ่ม (SQL/Enterprise/SMB), สรุปโจทย์ลูกค้า, ให้คะแนนลีด
- Action: สร้างโอกาสขายใน CRM, เปิดเคสใน Jira/Asana, แจ้งทีมเซลส์ใน Slack พร้อมสรุป 1 ย่อหน้า
- ทริก: ใช้ตัวแยกสาขา (routers) เพื่อคุมเงื่อนไข, แยก environment dev/prod, ทำ error handling (retry/backoff)
C) Google NotebookLM – ผู้ช่วยวิจัยที่อ้างอิง “ข้อมูลจริงที่มีอยู่”
ดีมากสำหรับงานที่ต้อง “สรุปจากแหล่งจริง” และสร้างสื่ออธิบาย (วิดีโอ/เสียง) จากเอกสารเราเอง
- บทบาทใน Workflow เป็น “เครื่องสรุป/อธิบาย/สร้างบทเรียน” จากเอกสารที่เราอัปโหลดเอง (ช่วยลด Hallucination เพราะยึดข้อมูลจากแหล่งของผู้ใช้)
- ฟีเจอร์เด่นล่าสุด: Video Overviews & Audio Overviews รองรับ ~80 ภาษา—แปลงโน้ต/เอกสารของเราเป็นวิดีโอ/ออดิโอสรุปได้ เหมาะกับการสรุปงาน/การเรียน/ออนบอร์ดทีม
- use case : ทีมคอนเทนต์อัปโหลดรีเสิร์ช/คู่มือผลิตภัณฑ์ → ให้ NotebookLM สร้างวิดีโอสรุป 7 นาที + สคริปต์ เพื่อนำไปต่อยอดฝึกอบรมทีม/พาร์ตเนอร์
D) Google Agentspace – แพลตฟอร์มธุรกิจขนาดใหญ่สำหรับ “เอเจนต์ + ค้นหาเอกสารองค์กร”
เหมาะสำหรับองค์กร—รวมเอเจนต์ + ค้นหาเอกสารองค์กรแบบปลอดภัย มี connector ให้ใช้หลากหลายและสิทธิ์ข้อมูลครบ เริ่ม $25/คน/เดือน
- จุดเด่น: ศูนย์กลางสร้าง/จัดการ/เผยแพร่ AI Agents ในองค์กร พร้อม enterprise search ที่ permission-aware และคอนเน็กเตอร์กับ Confluence, Jira, SharePoint, ServiceNow ฯลฯ (ดึงความรู้จากหลายที่ แต่เคารพสิทธิ์เข้าถึง)
- โมเดลการใช้งาน: มี Enterprise Plan เริ่มต้น $25/คน/เดือน (เหมาะกับองค์กรเริ่มต้นใช้เอเจนต์ในวงกว้าง)
- use case : Human resources agent ที่อ่านนโยบาย/KB ทั้งบริษัท → ตอบคำถามพนักงาน/ลูกค้า, เปิดเคส, ดึงอ้างอิงจากแหล่งเอกสารที่ถูกต้องตามสิทธิ์
E) A2A (Agent-to-Agent) ของ Google – โปรโตคอลให้เอเจนต์ “คุยและร่วมมือกัน”
เมื่ออยากสร้าง “ทีมเอเจนต์” หลายบทบาทที่คุยกันได้ตามมาตรฐาน และต่อยอดสู่มาร์เก็ตเพลสในอนาคต
- คืออะไร: มาตรฐานการสื่อสารระหว่างเอเจนต์ ให้แลกข้อมูล/ประสานงานข้ามแอปและแพลตฟอร์มได้อย่างปลอดภัย
- Ecosystem: มี Agent Development Kit (ADK) และคอนเทนต์/โค้ดแลบสอนแปลงเอเจนต์ให้รองรับ A2A + มีอัปเดต AI Agent Marketplace ให้พาร์ตเนอร์ขายเอเจนต์ได้ด้วย
- use case : ecommerce agent
- Agent A (Catalog) ตรวจสต็อก/ราคา
- Agent B (Support) ตอบลูกค้า-เปิดเคส
- Agent C (Marketing) สร้างแคมเปญส่วนลด
- ทั้งหมดคุยกันผ่าน A2A เพื่อปิดลูปงานแบบอัตโนมัติและตรวจสอบกันเอง
ข้อควรระวัง / Best Practices
- Grounding & Memory: ต่อ LLM เข้ากับแหล่งข้อมูลจริง (RAG) + เก็บความทรงจำในเวิร์กโฟลว์ (Redis/pgvector/เวกเตอร์ดาต้าเบส) เพื่อความแม่นยำ
- Guardrails: ตรวจความปลอดภัยของเนื้อหา, จำกัดขอบเขตคำสั่ง, ใส่ human-in-the-loop ในจุดสำคัญ
- ต้นทุน & ประสิทธิภาพ: บีบโทเค็น (สรุป/ย่อ), แคชผลลัพธ์, จัดลำดับงานหนัก (ภาพ/วิดีโอ) ให้รันแบบ async
- การจัดการเวอร์ชั่น : เก็บพารามิเตอร์โมเดล/พรอมป์ต์/ลอจิกเวิร์กโฟลว์ เพื่อดีบักและอัปเกรดภายหลัง
- สิทธิ์ข้อมูล: ใช้แพลตฟอร์มที่ permission-aware เมื่อต้องค้นเอกสารองค์กร (Agentspace) และระวังข้อมูลอ่อนไหวเสมอ
9.การใช้งาน AI ในรูปแบบต่าง ๆ
AI ไม่ได้มีเพียงการตอบข้อความ แต่สามารถถูกใช้งานได้ในหลายรูปแบบ ขึ้นอยู่กับความสามารถของโมเดลและงานที่ต้องการ เช่น
- Generative Text (ข้อความ): เช่น ChatGPT หรือ Google Gemini ใช้สำหรับเขียนบทความ แปลภาษา หรือสรุปข้อมูล
- Generative Image (ภาพ): เช่น MidJourney, DALL·E หรือ Stable Diffusion ที่สามารถสร้างภาพจากข้อความ
- Generative Audio (เสียง/เพลง): เช่น AI สร้างเสียงเลียนแบบมนุษย์ (Text-to-Speech) หรือสร้างเพลงใหม่จากแนวเพลงที่กำหนด
- Generative Video (วิดีโอ/อนิเมชัน): เช่น Runway ML หรือ Pika Labs ที่สามารถสร้างวิดีโอจากคำสั่ง
- AI สำหรับสายงานเฉพาะ:
- ด้านการแพทย์: ใช้ช่วยวิเคราะห์ผลเอกซเรย์หรือ MRI
- ด้านการตลาด: ใช้ทำนายแนวโน้มพฤติกรรมลูกค้า
- ด้านการศึกษา: สร้างคอร์สหรือเนื้อหาที่ปรับตามผู้เรียน
- ด้านวิศวกรรม/ออกแบบ: Generative Design ช่วยออกแบบชิ้นงานอัตโนมัติ
ตัวอย่าง: Google Vertex AI (ใน Google Cloud) ที่ทำหน้าที่เป็นแพลตฟอร์มรวมเครื่องมือ AI ครบวงจร เช่น การสร้างโมเดล Generative AI, การวิเคราะห์ข้อมูล หรือการ Deploy AI ไปใช้ในธุรกิจจริง
10. บทบาทของมนุษย์ (Human in the Loop)
แม้ว่า AI จะก้าวหน้าไปมากและสามารถทำงานที่ซับซ้อนได้อย่างรวดเร็ว แต่สิ่งสำคัญที่เราต้องตระหนักอยู่เสมอคือ AI เป็นเพียง "เครื่องมือ" อันทรงพลังที่ถูกสร้างขึ้นมาเพื่อเสริมศักยภาพมนุษย์ ไม่ใช่เพื่อทดแทนมนุษย์ได้ทั้งหมด 100%
AI มีความโดดเด่นในการประมวลผลข้อมูลจำนวนมหาศาล, ค้นหารูปแบบที่มนุษย์อาจมองข้าม, หรือสร้างสรรค์ไอเดียใหม่ๆ จากฐานข้อมูลที่มีอยู่ แต่ในขณะเดียวกัน ความสามารถของมนุษย์ในการคิดเชิงวิพากษ์, การตัดสินใจบนพื้นฐานของบริบททางสังคมและจริยธรรม, ความเข้าใจในอารมณ์ความรู้สึก, หรือการใช้สามัญสำนึก ยังคงเป็นสิ่งที่ AI ไม่สามารถเลียนแบบได้อย่างสมบูรณ์
ดังนั้น การใช้งาน AI ที่มีประสิทธิภาพสูงสุดและน่าเชื่อถือจึงต้องอาศัย "Human in the Loop" หรือการที่มนุษย์มีบทบาทสำคัญในการกำกับดูแล ตรวจสอบ และชี้นำ AI ตั้งแต่ต้นจนจบ มนุษย์จะทำหน้าที่เป็นผู้กำหนดโจทย์, ประเมินผลลัพธ์, และปรับปรุงแก้ไข เพื่อให้ AI ทำงานได้ตรงตามวัตถุประสงค์และตอบสนองความต้องการที่แท้จริง
AI ที่ดีที่สุดคือ AI ที่ "ทำงานร่วมกับมนุษย์" ในลักษณะของการเป็นผู้ช่วยอัจฉริยะ ไม่ใช่การเข้ามา "แทนที่มนุษย์" โดยสิ้นเชิง อย่างไรก็ตาม การที่มนุษย์จะสามารถทำงานร่วมกับ AI ได้อย่างมีประสิทธิภาพนั้น ก็จำเป็นต้องมีพื้นฐานความรู้ความเข้าใจในเนื้อหาที่ตนเองกำลังทำงานอยู่ รวมถึงมีความสามารถในการตั้งคำถามและสื่อสารกับ AI ได้อย่างชัดเจน หากปราศจากความรู้พื้นฐานเหล่านี้ การพึ่งพา AI อย่างเดียวอาจนำไปสู่ผลลัพธ์ที่ไม่แม่นยำ หรือแม้กระทั่งทำให้กระบวนการทำงานช้าลงกว่าเดิม เนื่องจากต้องเสียเวลาในการแก้ไขและตรวจสอบซ้ำหลายครั้ง
นอกจากนี้ การตรวจสอบความถูกต้องของผลลัพธ์ที่ได้จาก AI ถือเป็นสิ่งสำคัญอย่างยิ่ง เพราะ AI เรียนรู้จากข้อมูลในอดีต ซึ่งอาจมีอคติหรือข้อผิดพลาดแฝงอยู่ มนุษย์จึงต้องใช้ความเชี่ยวชาญและวิจารณญาณในการคัดกรองและยืนยันข้อมูล เพื่อให้มั่นใจว่าผลลัพธ์ที่นำไปใช้นั้นมีความถูกต้อง แม่นยำ และเป็นประโยชน์สูงสุดอย่างแท้จริง
สุดท้ายนี้ ผมหวังว่าบทความนี้จะช่วยให้คนที่เพิ่งเริ่มใช้ AI เข้าใจ “จุดแข็ง” และ “ข้อจำกัด” ก่อนใช้งานจริง ไม่มากก็น้อย แต่อยากให้ทุกคนได้รับรู้หลักการเบื้องต้นทั้งหมดก่อนพิจารณา
ลองใช้ AI ได้แล้ววันนี้ ทั้ง Gemini , Chat GPT ครับ ไม่มีคำสั่งไหนที่สมบูรณ์แบบ 100% คุณต้องทดลองมันด้วยตัวเองเท่านั้นครับ แล้วเจอกันใหม่บทความหน้า